决策边界
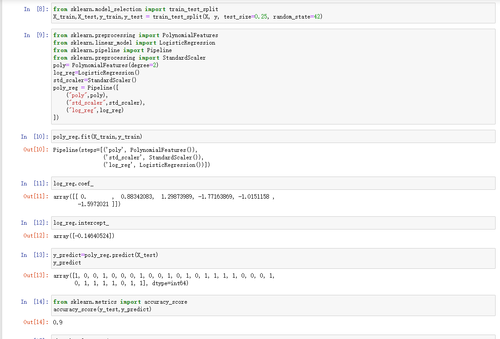
老师,您好。我对数据进行了train_test_split后再预测,发现准确率比较低,为了提高准确率,我依次进行了PolynomialFeatures(degree=2),StandardScaler(),LogisticRegression()的操作,最后准确率达到了0.9。但在绘制决策边界时出现了图片中的情况。去除了StandardScaler()这一步能够得到正常的决策边界。但是准确率只有0.67。请问如果要保留StandardScaler(),应该怎样绘制出正常的决策边界?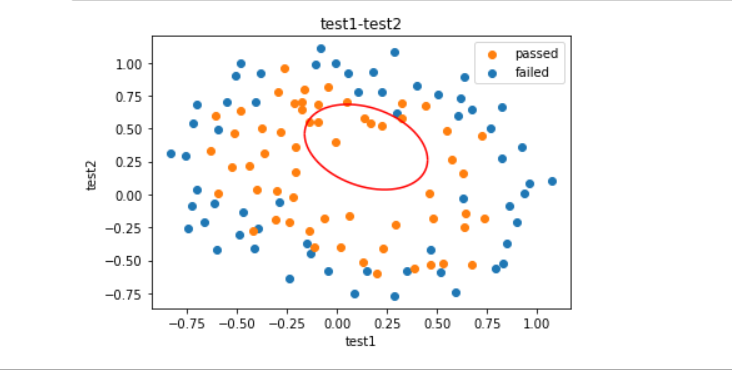
1191
收起
正在回答 回答被采纳积分+3
2回答


相似问题
为什么SVM这个例子中“距离决策边界最近的点”是3个?
1898
0
5


把y=1的点都聚在一起,决策边界还是没有变化?
1200
0
3
关于决策树的决策边界
2583
0
2


决策边界和sigmoid的关系
1551
0
1
关于精准率和召回率的平衡点似乎都是在0左右
881
0
2
登录后可查看更多问答,登录/注册












