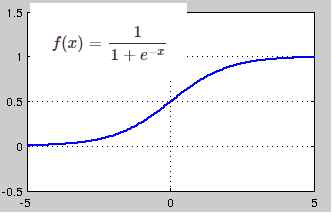
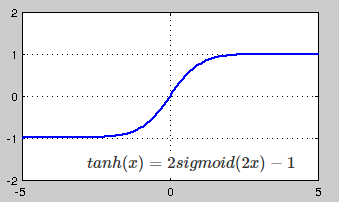
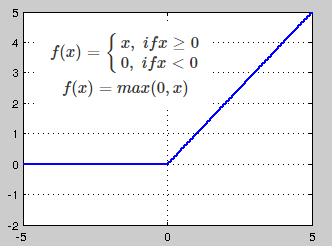
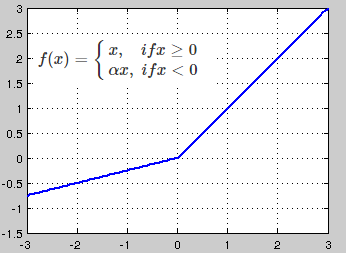
Sigmoid对比ReLU
不太清楚这个问题放在这里是否合适。现在机器视觉中是不是已经不再使用Sigmoid转而使用ReLU了?我以前得到的解释是使用Sigmoid会让训练变得很困难,所以Sigmoid是比较传统的方法,而现在基本都用ReLU,我还见过使用Leaky ReLU。老师是否可以解释一下?
3402
收起
正在回答
2回答

相似问题
在xor这章中,这里为什么第一层激活函数用的relu
1047
0
5


老师,关于激活函数relu
1174
0
3


为什么conv+bn+relu是有效的?
10896
2
1
关于激活函数 的问题
1220
1
1
关于relu和leakyrelu的问题
3073
0
2
登录后可查看更多问答,登录/注册












