元宵节快乐
老师,又学习了一章节新的东西,谢谢老师。老师我比较笨,我有几个问题想下;
第0个,老师的两个案例都是 只有两个特征向量,也就是theta1和theta2,
如果有多个,那么可视化的时候应该怎么可视化,我比较困惑,是像第二章一样线性回归一样,看每两个变量的二维图。
一,老师讲了梯度下降,那么他的步伐那个a,具体表现在哪里,scklearn里面会自己优化这个梯度下降的算法吗?还是在对象的方法中有默认的值。
二。逻辑回归只是针对二分类吗,对多分类还是得用神经网络,决策树那些吗?
二,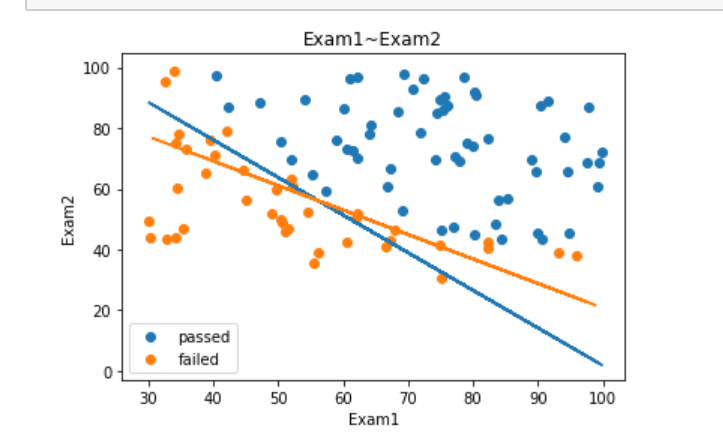
老师求的x2,我试着求了下x1,然后我就晕了。。我开始不理解,为什么要用x2_new = -(theta0+theta1*x1)/theta2这个,为什么要用已知的x1去推未知的x2_new,求出的意义又是什么?
三,老师辛苦,元宵节快乐!昨天太累了。没看,今天抓紧时间看了下,很期待老师后面的课程!
1754
收起
正在回答
2回答


相似问题
老师,编辑页面放大的快捷键是??就像下图那样的
1092
2
2




z-index不是只能在定位元素上使用吗?
2180
0
8




#margin > p 是不错错了,正确是不是 #margin p?
1629
1
10


老师节日快乐!!!谢谢老师!
828
0
1
关于课程示例代码中快速查找指定位置元素的效率问题
956
0
2


登录后可查看更多问答,登录/注册











