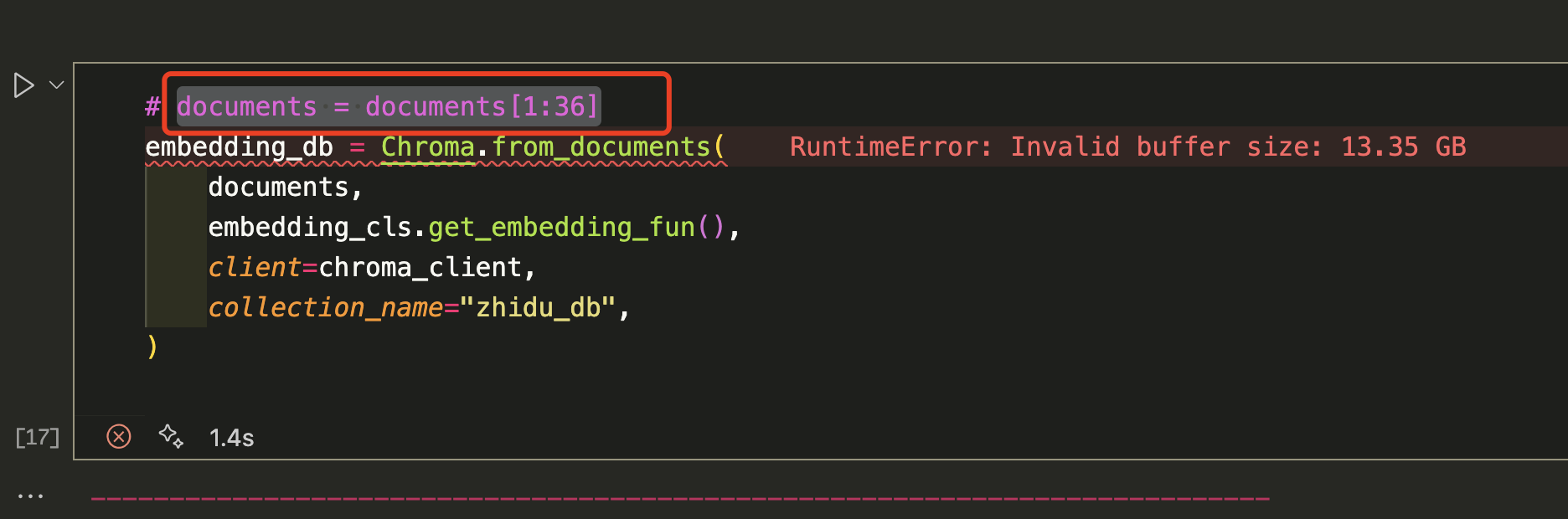
baseline documents 入库,提示buffer size 太大,13.35G
是不是表格数据:
<table><caption>伙食补助费参考以下标准:</caption>\n<tr><td >地区</td><td >伙食补助费标准</td></tr>\n<tr><t...
向量化时候有什么异常???
我用的是mac m1的机器, device是cpu;
把documents切片后正常:documents = documents[1:36],正常, 36后面的是表格数据,documents = documents[1:39]就会一直运行中,不切片会报错 buffer size 太大,13.35G
222
收起
正在回答
1回答

相似问题
documents这个文件夹是不能复制吗?这是一个文件夹吗
417
1
6


Buffer提交
918
0
3


关于从 IoArgs 向 byte 中写入的问题
868
1
6




传递buffer太过累赘的疑问
917
0
1
输入z.cn 提示:“服务内部错误”
1135
0
3


登录后可查看更多问答,登录/注册




