部署项目

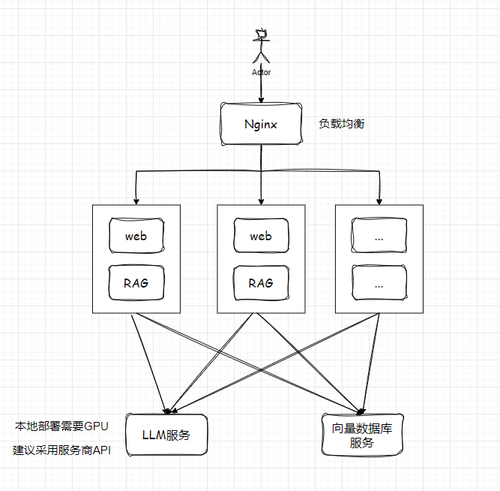
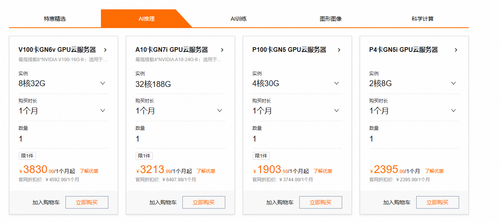
老师,您好!我想用这套技术搭建一个中小型的企业,制度问系统,在没有硬件服务器资源的情况,可以用这技术部署在云服务器上吗?采用什么云服务器好呢,采用什么云服务器配置,保证这个系统能应付200个并发提问。劳烦老师指导。
441
收起
正在回答
2回答


相似问题
老师,这个项目部署用到docker容器了吗?
424
0
3


项目写完后上线的部分完全找不到啊
1120
0
3


Gerapy部署Scrapy项目报错
1006
0
3
关于项目部署问题
1402
1
3


登录后可查看更多问答,登录/注册




