采纳答案成功!
向帮助你的同学说点啥吧!感谢那些助人为乐的人
老师,ollama部署minicpm,尝试了很多配置参数,始终只在一张显卡上加载。如何均匀分摊到多卡?我尝试过vllm,但分词器不兼容。有什么更好的建议?
hi,你好!你显卡的显存大小是多少?minicpm模型大小大概6G中,普通的11G显存一张卡就可以装得下。ollama只有在显存不足的情况才会分配到其他的显卡。需要明确的一点就是:如果一张卡可以加载模型,没有必要多卡部署。多卡部署其实要做模型的切分,会导致推理变慢(因为要多做卡和卡之间的通信)
---------------------------------------------------
如果是vllm(我这边的vllm是0.11.0版本 minicpm-v 4.5版本)
(如果是int4量化的模型)可以采用数据并行或者流水线并行开启利用多卡设备
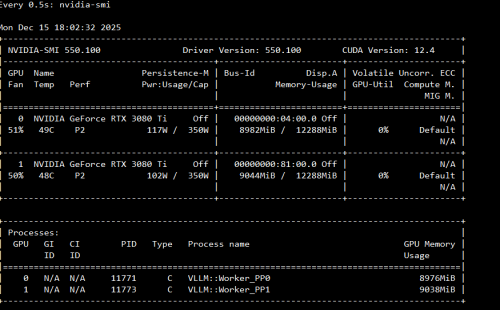
我是8张4090,因为已经部署了qwen32b,每张卡都只剩3-4G,而ollama启动minicpm时默认只使用第一张卡,导致有时候卡一会报显存不足。所以我才想着将minicpm也均分到多卡。您的意思是vllm 0.11.0 minicpm-v 4.5是可以多卡部署吗?我的vllm是0.9.
如果是vllm 如果是tensor 并行是可以多卡部署。有一个疑问是你4090是24G显存吗?qwen32b只要4个卡就够了吧?ollama可以也可以执行显卡 比如 export CUDA_VISIBLE_DEVICES=1,2
回复 阿基米口:我token、张量并行这些参数设置得比较大。不过本质问题还是如何多卡运行minicpm?CUDA_VISIBLE_DEVICES=1,2这个我试过,好像不生效。vllm框架的话只有部署适配的模型了。
登录后可查看更多问答,登录/注册
RAG全栈技术从基础到精通 ,打造高精准AI应用
652 8
342 8
501 7
1.4k 7
688 7
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号