采纳答案成功!
向帮助你的同学说点啥吧!感谢那些助人为乐的人
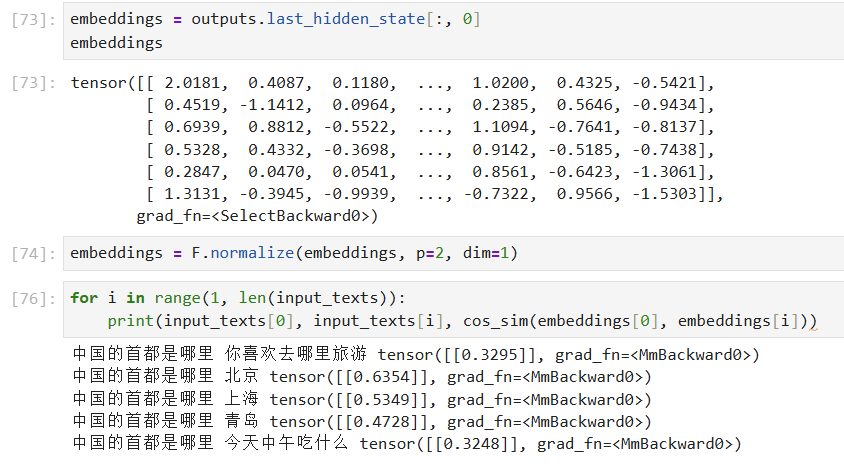
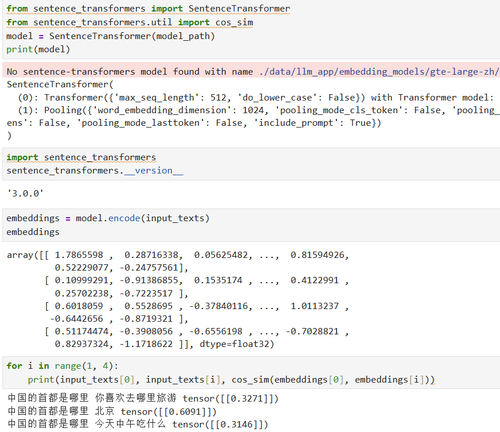
0.63, 0.60, 0.60后面的两个方法结果一样,但是和视频里展示的不一样
你好,从你SentenceTransformer中的模型结构来,
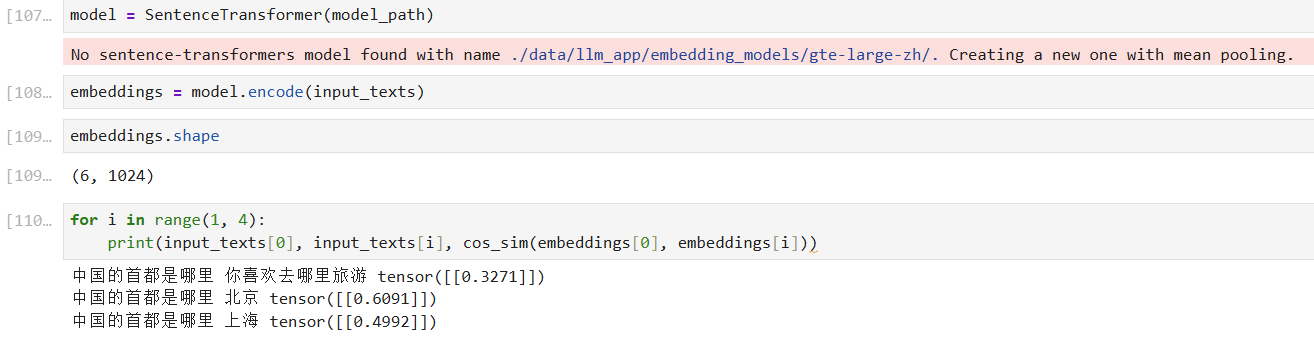
SentenceTransformer中计算句子embedding的方式是采用所有token的均值('pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True)。
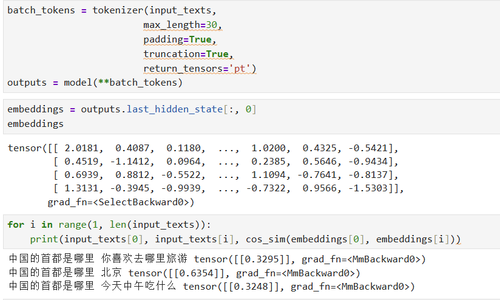
而第一种方式中:是采用cls分类token来表示整个句子的embeeding(也就是BERT架构的CLS token)(outputs.last_hidden_state[:, 0] 第一个token)。导致这两种计算方式不一样,也可以通过调整参数来保持一致
可以通过调整SentenceTransformer结构中的pooling方式,把SentenceTransformer改成cls token的方式
from sentence_transformers import SentenceTransformer, models model_path = './data/llm_app/embedding_models/gte-large-zh/' model = SentenceTransformer(model_path) # 创建新的 Pooling 层,修改 pooling_mode_cls_token 和 pooling_mode_mean_tokens pooling = models.Pooling( word_embedding_dimension=1024, # 保持与原来一致 pooling_mode_cls_token=True, # 修改为 True 或 False pooling_mode_mean_tokens=False, # 修改为 True 或 False pooling_mode_max_tokens=False, pooling_mode_mean_sqrt_len_tokens=False, pooling_mode_weightedmean_tokens=False, pooling_mode_lasttoken=False, include_prompt=True ) model._modules['1'] = pooling
这样模型的结构就调整成cls token来计算pooling
可以试下
非常感谢!
embeding不一样
你好,从你SentenceTransformer中的模型结构来,SentenceTransformer中计算句子embedding的方式是采用所有token的均值('pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True)。而第一种方式中:是采用cls分类token来表示整个句子的embeeding(也就是BERT架构的CLS token)(outputs.last_hidden_state[:, 0] 第一个token)。导致这两种计算方式不一样,也可以通过调整参数来保持一致,见上面最新回复的代码
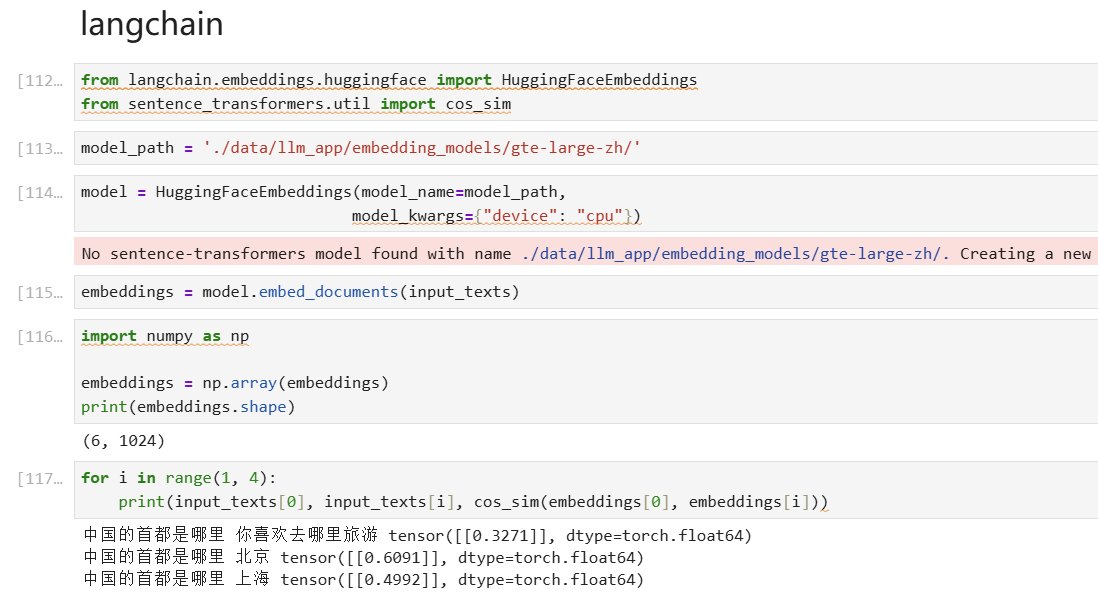
Sentence-Transformers和huggingface结果一样是正常的,huggingface中的embedding是Sentence-Transformers的封装。
我这边重复执行三个都是一样的,所以需要你这边打印一些信息来看看区别
把三个model 的结果都打印出来看看 直接print就可以
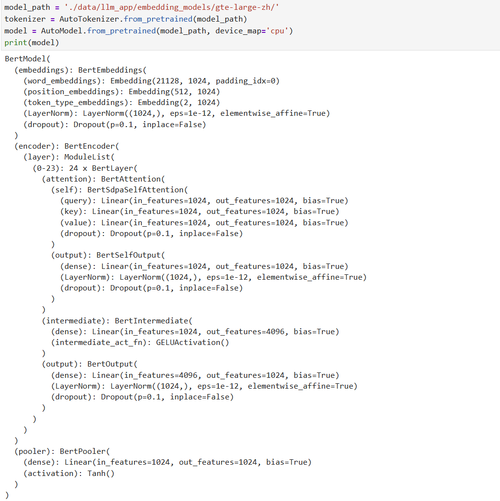
model_path = './data/llm_app/embedding_models/gte-large-zh/' tokenizer = AutoTokenizer.from_pretrained(model_path) model = AutoModel.from_pretrained(model_path, device_map='cpu') print(model)
model = SentenceTransformer(model_path) print(model)
把embeding打印出来
提供下sentence_transformers的版本
import sentence_transformers sentence_transformers.__version__
老师您好,这个回复对话框无法上传图片,我直接新建了一个“回答”
好的!
登录后可查看更多问答,登录/注册
RAG全栈技术从基础到精通 ,打造高精准AI应用
652 8
342 8
501 7
1.4k 7
689 7
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号