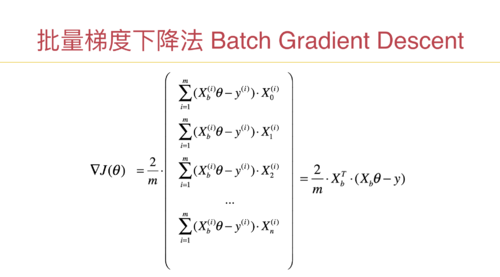
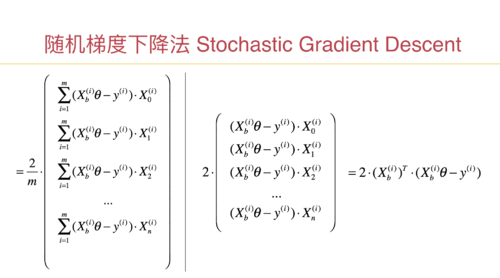
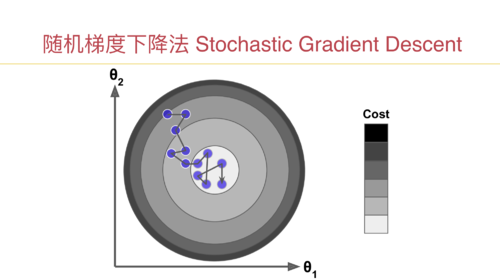
随机梯度下降法
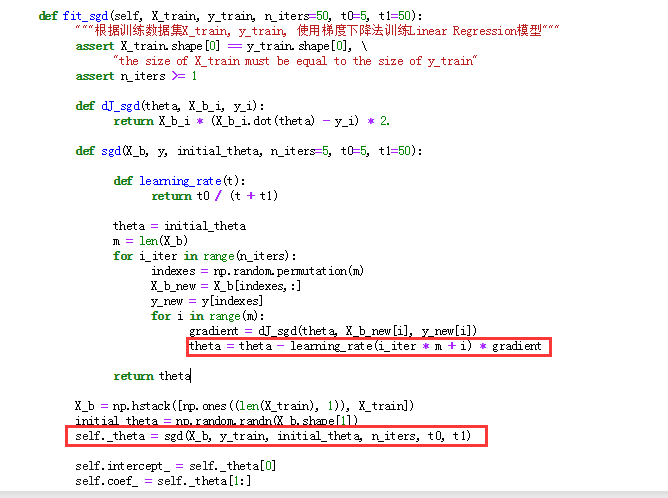
老师,这个逻辑理解的不是很透彻,第一个疑问是:随机梯度下降法涉及到多维特征的时候,我们每次都只取一行数据来计算,不太能在脑子里形成画面,这个时候就相当于在每个维度上取了一个特征点,然后多少个特征就相当于在多维空间中有多少个分布的特征点,由于采用了数据归一化,可以想象的到这些点特征值是在0~1之间,(1)这些特征点是一个线性的关系吗?(2)这些特征点所形成的损失函数图像是一个类似于二次幂函数的图像吗?因为之前我们的二次幂的损失函数图像(J)是一个特征多个样本的,还可以理解,但是现在这时候样本数据就选了一个,特征是有多个的,就有点理解不动了,思维也想象不到梯度的轨迹是怎么样的,不太理解ppt里面曲线的运动轨迹,这个随机梯度法能不能实现代码模拟绘图可以形象的看到。(3)不知道关于这个些疑问的学习方法和思考方向是不是对的,请老师指点一下,
第二个疑问是:随机梯度下降法运动轨迹有时候是正常的方向,有时候折回来了,(theta = theta - learning_rate(i_iter * m + i) * gradient )是因为此时theta值小于learning_rate(i_iter * m + i) * gradient 导致theta值是负数的原因吗 就相当于是这时候遇到了局部最优解,前面出现了一个坡度,此时是从局部最优解往全局最优解移动的一个过程,所以走了回头路。
1404
收起
正在回答
1回答
相似问题
两种梯度下降法的速度比较
1914
0
5


该怎么理解随机梯度必然会下降这个操作?
2029
2
4
关于小批量梯度下降算法与改进之后的随机梯度下降算法
1289
0
3
随机梯度下降法计算性能的疑问
1447
2
4


登录后可查看更多问答,登录/注册








