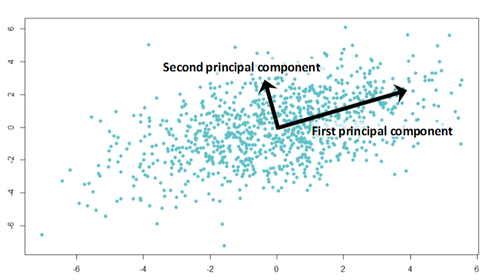
PCA降维的把握和依据分别是什么?比如把一个近似直线分布的二维点数据降维成直线?
老师,那个PCA把二维的点降维成一条直线,为什么可以这么做?
想不明白,事先又不知道真实数据是不是直线?是因为:
这些点本来就是近似直线的?如果是近似直线的,我们是怎么知道这些点的原始数据是近似直线的?
看着近似直线就可以看作直线吗?尽管他们原始数据可能就不是直线就是分散的,如果这样,拟合成直线是否有意义?
降维正确性的评价标准是什么?
降维除了PCA还有其他方法吗,感觉PCA不太直观
3436
收起
正在回答
1回答
相似问题
什么样的数据适合使用pca降维
3408
1
4


降维处理
1328
0
4


每个映射的坐标轴方向向量w有n个元素,是不是说w是n维空间的一个向量?
1650
2
7
为什么去掉第1主成分后X2数据维度没有降低?
1915
4
5


PCA降维的维度问题
2229
3
7
登录后可查看更多问答,登录/注册








