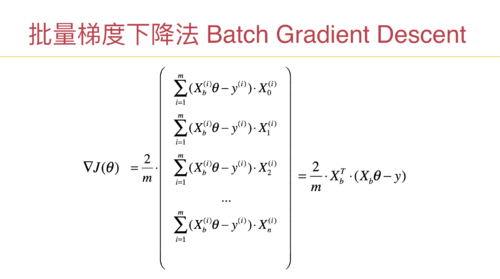
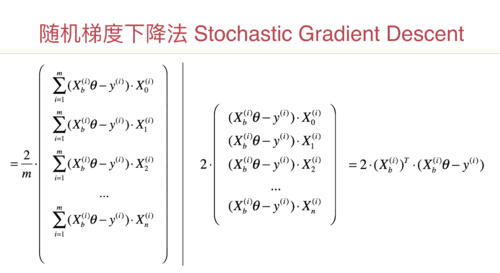
随机梯度下降法计算性能的疑问
在视频里n_iters的取值为样本数量的整数倍,但是这样随机梯度下降法的计算量可能会比批量梯度下降法大吧,那为什么不直接用批量梯度下降呢?
1471
收起
正在回答 回答被采纳积分+3
2回答

相似问题
关于小批量梯度下降算法与改进之后的随机梯度下降算法
1306
0
3


两种梯度下降法的速度比较
1927
0
5
该怎么理解随机梯度必然会下降这个操作?
2049
2
4
随机梯度下降法
1409
1
5
登录后可查看更多问答,登录/注册








