两种梯度下降法的速度比较
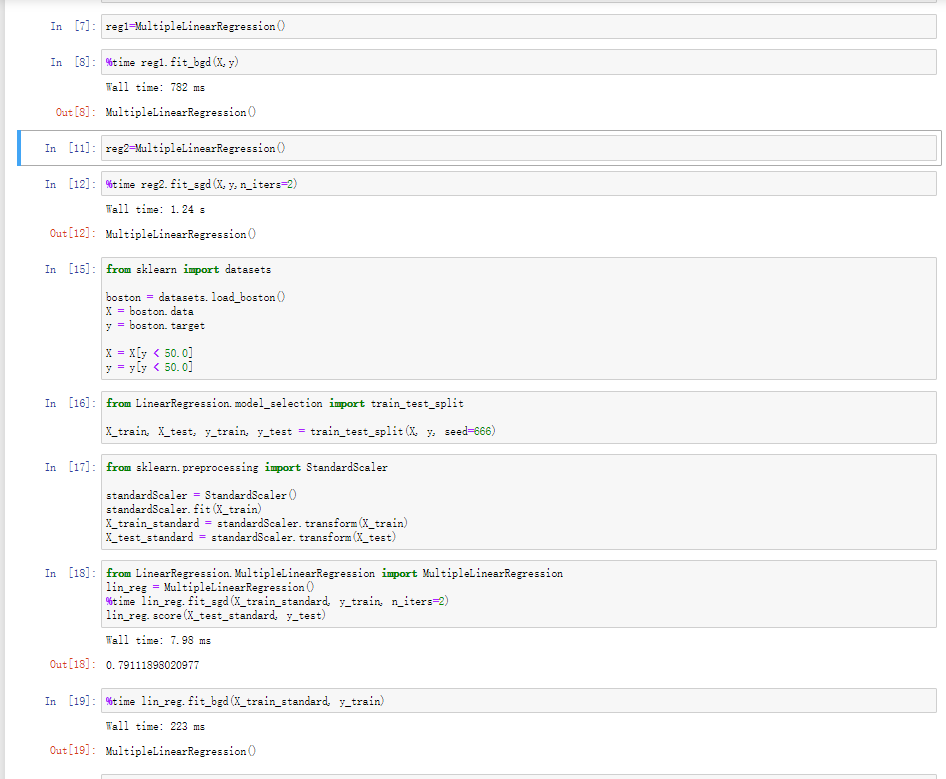
请问老师为什么在自己构造的数据中批量梯度下降法比随机梯度下降法快,而对于已经归一化处理的波士顿房价数据集随机梯度下降法比批量梯度下降法快?
2024
收起
正在回答
1回答
相似问题
关于小批量梯度下降算法与改进之后的随机梯度下降算法
1412
0
3


随机梯度下降法计算性能的疑问
1571
2
4


leastsq是用的梯度下降法吗
1123
0
3


该怎么理解随机梯度必然会下降这个操作?
2164
2
4
梯度下降法和梯度上升法的收敛情况
2145
1
3
登录后可查看更多问答,登录/注册








