关于如何提起文档中的图片
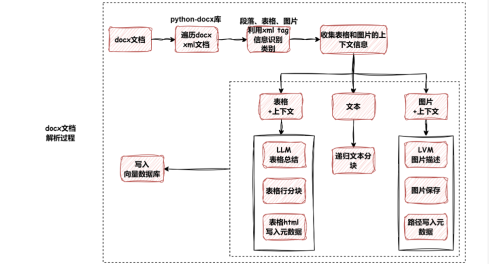
你好老师,最新在寻思着将手册指南类的docx文档进行解析,包含图片这种(先不考虑图片内容识别,图片的意思根据最近上面段落的意思走),在回答是也能将图片进行输出。这种是不是在做向量化计算的时候需要将图片上传之后的url也进行计算然后一块向量化,但是这个感觉会影响向量换化计算的结果,因为url本身是没有语义信息的,像这种一般怎么处理比较好呢,还有我的技术栈主要集中在Java,对于这种解析图文混编的没有成熟框架,得自己写,像python有吗?
293
收起
正在回答 回答被采纳积分+3
1回答

相似问题
vue 如何做图片上传功能
2098
0
7




html里img引用图片问题
1213
0
4


关于文档的疑问
1489
1
4


data.json文件中的图片路径如何更改
945
0
4
srcary下载图片,封面及详细页图片分开下载,如何使用默认下载组件
1201
0
9




登录后可查看更多问答,登录/注册




