srcary下载图片,封面及详细页图片分开下载,如何使用默认下载组件
老师,还有个小问题,如下
scrapy爬取网站的时候,网站一般会有封面图片跟详细内容图片,如何能分2个字段入库,并下载,我按我们教程来,有一个折中办法就是将获取的字段都放在一个字段中,如下面这样写:
images = response.meta.get("image","")
pics = response.xpath("//div[@class='swiper-wrapper']//img/@src").extract()
pics.append(images)
item_loader.add_value("pics", pics) # 获取图集
问题来了,这样写不够简洁也不方便后期维护,这个第一,第二是pipelines.py中配置下面这样才能获取修改后的路径,看着都觉得蛋疼(因为入库要分开2个字段,方便直接发布)
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
if "image" in item: # 查看item是否有图片字段
for ok, value in results: # 遍历图片字段
image_file_path = value["path"] # 将遍历的字段赋值
item["image"] = image_file_path # 将图片路径保存在item字典中
if "pics" in item: # 查看item是否有图片字段
pics_list = []
for ok, value in results: # 遍历图片字段
pics_file_path = value["path"] # 将遍历的字段赋值
if pics_file_path == item["image"]:
pass
else:
pics_list.append(pics_file_path)
item["pics"] = ",".join(pics_list) # 将图片路径保存在item字典中
return item
有什么好的办法解决,折腾了几天了,没想到更好的代码分离方法
1208
收起
正在回答
3回答

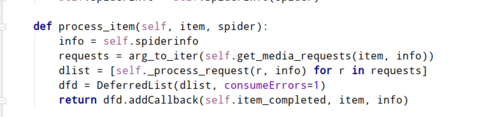 ,这个代码在
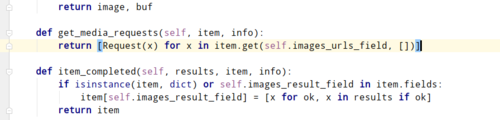
,这个代码在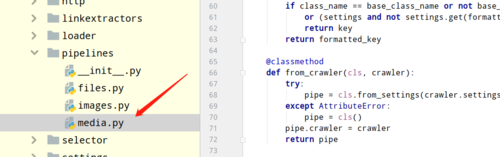 这个文件中,你顺着上面的process_item中的源码找到关键源码就知道scrapy是如何处理图片的了,然后自己改一下就行了
这个文件中,你顺着上面的process_item中的源码找到关键源码就知道scrapy是如何处理图片的了,然后自己改一下就行了

相似问题




登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











