梯度下降法和梯度上升法的收敛情况
波波老师,我想问下,就是梯度下降法和梯度上升法,最终迭代后梯度是不是都会趋向于0?还是说两者的情况不一样。我自己就2维和3维上的感觉而言,迭代到最后找到的最小值(最大值),它在代价函数上的相应梯度都应该接近0才对。那本节课里面使用的梯度上升法,迭代到最后得到最大值结束的那几个几个梯度都是挺大的。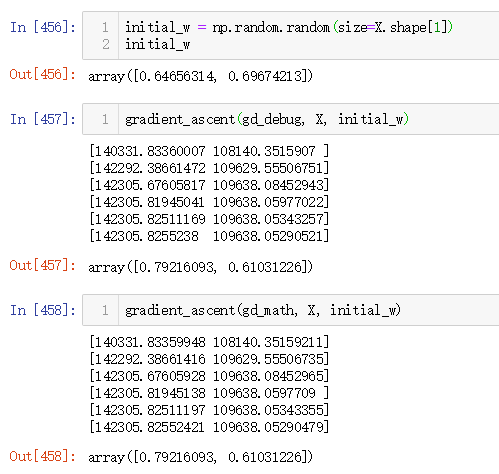
造成这样的情况是不是单位化w的原因?还是说,我本身对迭代到最后梯度应该趋向于0的理解有问题?
2145
收起
正在回答
1回答
相似问题
两种梯度下降法的速度比较
2023
0
5


关于小批量梯度下降算法与改进之后的随机梯度下降算法
1412
0
3
该怎么理解随机梯度必然会下降这个操作?
2164
2
4
leastsq是用的梯度下降法吗
1123
0
3


随机梯度下降法计算性能的疑问
1571
2
4


登录后可查看更多问答,登录/注册








