【随机梯度下降法】X特征量对R2score的影响
老师对不起(>人<;),又要麻烦您了。
在上一次您给我指出数据未进行归一化,进行计算导致程序准确率低,我进行改正就愉快地进行测试了。
在调整m(X的训练量)和n(X的特征数量)参数测试效率的过程中,我惊讶地发现在n越来越大的情况下,准确率会极速下降,而sklearn算法则不会影响,我在想我们实现随机梯度下降法的方式是不是有些许问题,我的代码在n大于60左和从bobo老师那复制的代码在n变大了之后,准确率也都会急速下降,而sklearn则没影响,这个问题我解决不了,也不知道这个问题是否适合我这个阶段研究,不适合我就果断跳过先,
python代码
代码有点多
写出来冗杂,和上一个问题用的是一样的
https://coding.imooc.com/learn/questiondetail/274363.html
jupyter Notebook代码
准备工作
import numpy as np
import matplotlib.pyplot as plt
#这个是我写的线性回归的代码
from nike.LinearRegression import LinearRegression
#这个是从bobo老师哪里复制的线性回归的代码
from nike.LinearRegression import LinearRegression2
定义数据初始化函数
def init(m,n):
#初始化数据
np.random.seed(666)
X = np.random.random(size=(m,n))
true_theta = np.arange(X.shape[1]+1,dtype=float)
X_b = np.concatenate([np.ones((len(X),1)),X],axis=1)
#对y不加噪点,我觉得数据量可能有点大算的有点慢
y = X_b.dot(true_theta)
#归一化+分割数据
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
standard = StandardScaler()
standard.fit(X_train)
X_train_standard = standard.transform(X_train)
X_test_standard = standard.transform(X_test)
return X_train_standard, X_test_standard, y_train, y_test
绘制n与socre的曲线
#我自己写的代码
score_history=[]
reg1 = LinearRegression()
#将数据从1-100逐级递增,计算代码准确率并记录,用于绘制n与socre的图形
for i in range(1,120):
X_train_standard, X_test_standard, y_train, y_test=init(1000,i)
reg1.fit_sgd(X_train_standard, y_train)
score_history.append(reg3.score(X_test_standard, y_test))
#绘制图形
plt.plot([i for i in range(len(score_history))],score_history)
plt.axis([0,100, -3,1.2])
plt.xlabel('n')
plt.ylabel('R2-Score value')
plt.show()
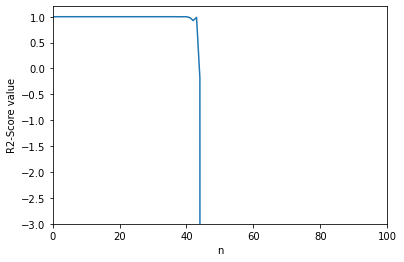
#从bobo老师那里复制的代码
score_history=[]
reg2 = LinearRegression2()
#将数据从1-120逐级递增,计算代码准确率并记录,用于绘制n与socre的图形
for i in range(1,120):
X_train_standard, X_test_standard, y_train, y_test=init(1000,i)
reg2.fit_sgd(X_train_standard, y_train)
score_history.append(reg2.score(X_test_standard, y_test))
#绘制图形
plt.plot([i for i in range(len(score_history))],score_history)
plt.axis([0,100, -3,1.2])
plt.xlabel('n')
plt.ylabel('R2-Score value')
plt.show()
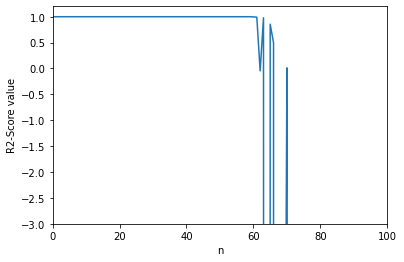
#机器学习sklearn
from sklearn.linear_model import SGDRegressor
score_history=[]
reg3 = SGDRegressor()
#将数据从1-120逐级递增,计算代码准确率并记录,用于绘制n与socre的图形
for i in range(1,120):
X_train_standard, X_test_standard, y_train, y_test=init(1000,i)
reg3.fit(X_train_standard, y_train)
score_history.append(reg3.score(X_test_standard, y_test))
#绘制图形
plt.plot([i for i in range(len(score_history))],score_history)
plt.axis([0,100, -3,1.2])
plt.xlabel('n')
plt.ylabel('R2-Score value')
plt.show()

1451
收起
正在回答
1回答
相似问题
关于小批量梯度下降算法与改进之后的随机梯度下降算法
1418
0
3


两种梯度下降法的速度比较
2027
0
5
随机梯度下降法计算性能的疑问
1575
2
4


该怎么理解随机梯度必然会下降这个操作?
2167
2
4
登录后可查看更多问答,登录/注册








