关于使用随机梯度下降法训练模型时出现的问题
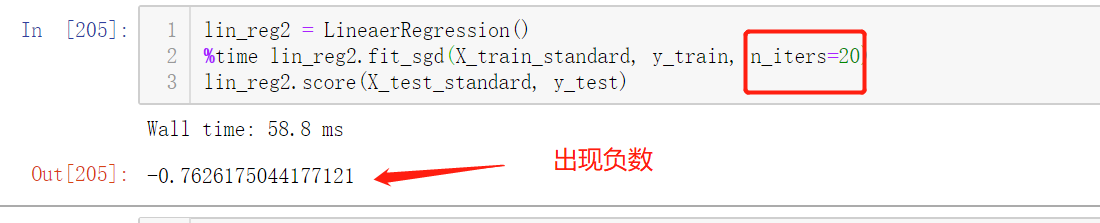
不断重复运行图中代码,大多数值都是趋近0.8,但是无论n_iters参数设置多大,都有可能出现负数,只是出现概率的问题,请问遇到这种情况有没有好的解决方法呢?
839
收起
正在回答 回答被采纳积分+3
1回答
相似问题
关于小批量梯度下降算法与改进之后的随机梯度下降算法
1244
0
3


两种梯度下降法的速度比较
1891
0
5
该怎么理解随机梯度必然会下降这个操作?
1996
2
4
随机梯度下降法计算性能的疑问
1410
2
4


登录后可查看更多问答,登录/注册








