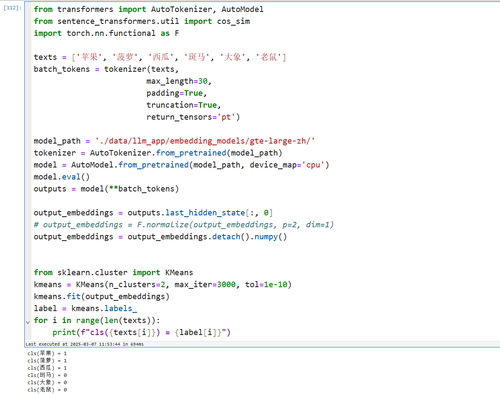
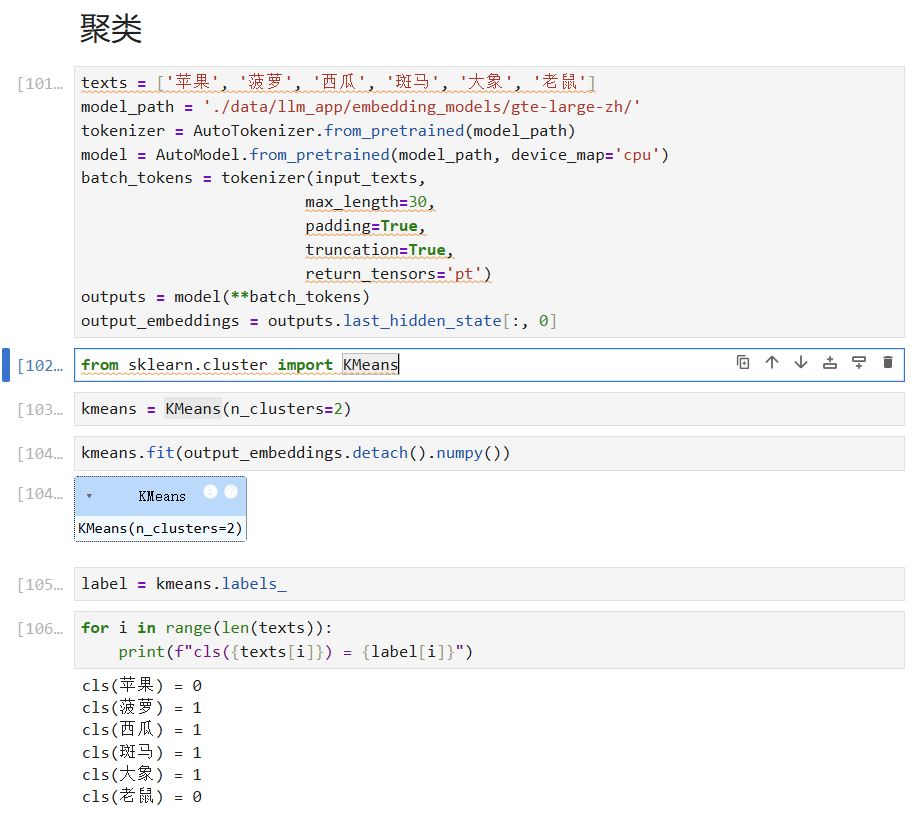
另外一个,我也试了下第一种的,确实是有可能存在聚类错误的情况(有一定的概率随机性),主要的原因:
最主要是这个具体类的样本太小了,kmeans算法本身存在初始聚类中心的随机选择,会导致结果可能存在不太一样。可以尝试加大迭代次数max_iter和收敛结束条件
from transformers import AutoTokenizer, AutoModel
from sentence_transformers.util import cos_sim
import torch.nn.functional as F
texts = ['苹果', '菠萝', '西瓜', '斑马', '大象', '老鼠']
batch_tokens = tokenizer(texts,
max_length=30,
padding=True,
truncation=True,
return_tensors='pt')
model_path = './data/llm_app/embedding_models/gte-large-zh/'
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, device_map='cpu')
model.eval()
outputs = model(**batch_tokens)
output_embeddings = outputs.last_hidden_state[:, 0]
# output_embeddings = F.normalize(output_embeddings, p=2, dim=1)
output_embeddings = output_embeddings.detach().numpy()
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, max_iter=3000, tol=1e-10)
kmeans.fit(output_embeddings)
label = kmeans.labels_
for i in range(len(texts)):
print(f"cls({texts[i]}) = {label[i]}")
也可以把向量的相似度矩阵打印出来(这个是每次执行都一样的)
# 打印下两两的相似度矩阵
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
similarity_matrix = cosine_similarity(output_embeddings)
print("cos相似度矩阵:\n",similarity_matrix)import numpy as np
from scipy.spatial.distance import cdist
vectors = output_embeddings
distance_matrix = cdist(vectors, vectors, metric='euclidean')
print("欧式距离矩阵:\n", distance_matrix)