关于标准化的几个问题
看了7.3节、7.5节和本节的课程,以及问答区里的一些内容后,对标准化这一问题仍然吃得不是很透,存在几个方面的问题,还望老师或其他大牛帮忙解答 :)
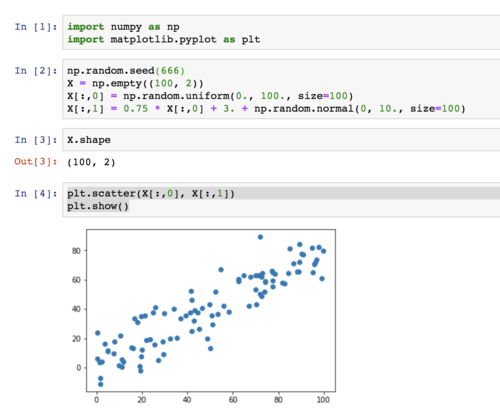
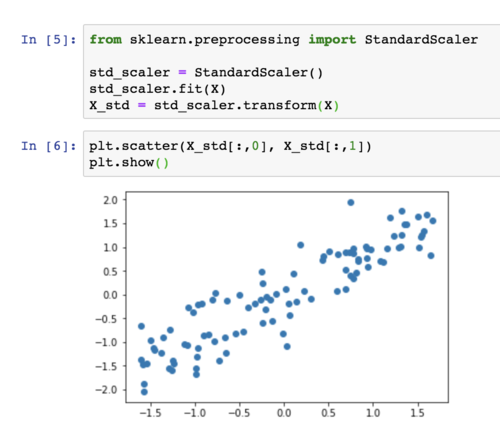
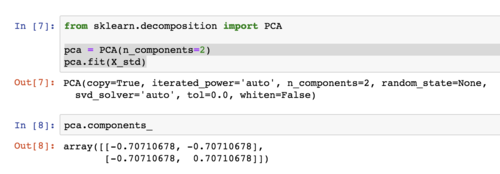
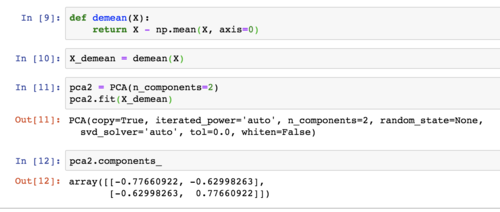
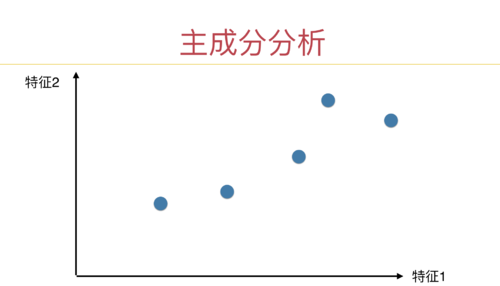
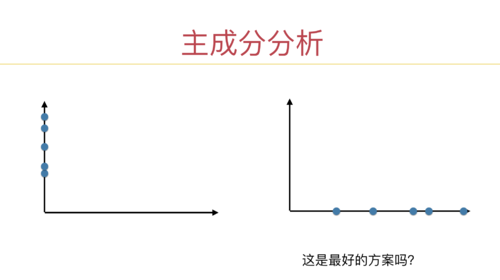
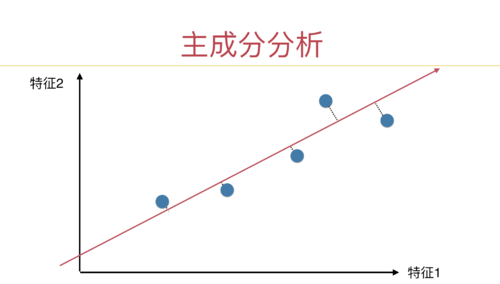
1、课程中说做PCA之前不用标准化,在问答区中有同学提出了不同意见;浏览了问答区的相关内容后,还是不明白为什么不能标准化。如果有三个样本,每个样本有两个维度,其中一个维度的样本数值分别为1、2、3,而另一个维度的样本数值分别为10000, 10100、10200,虽然后者方差更大,但前者更能体现数据之间的差异;不做标准化的PCA的结果使得主成分轴极度倾斜,降维后的数据基本上体现的是后一维度的内容,前一维度的信息很大程度上被丢弃了,这样是否合理?这一问题如何克服?如果说均值方差标准化使得数据变得非线性了而导致不能再进行PCA,那有没有什么其他的标准化方法可以替代它呢?
2、老师在https://coding.imooc.com/learn/questiondetail/98019.html中提到了主成分轴极度倾斜的问题,并提出在降维之后可以对低维数据做标准化处理。这里我不明白的是,做完PCA之后,进行knn判别之前,如果用均值方差标准化对数据进行处理,那每一个维度的方差都变成1了,而PCA的作用就是找到方差最大的几个主成分,那这样一来,做PCA的意义又何在呢?这和从原始数据里随便取出k个维度的数据,然后对每个维度做均值方差标准化有什么差别呢?最终得到的结果都是k个方差为1的序列不是吗?这就是我另外一个不太明白的地方
3、在实际生产工作中会发现,某些维度方差大,往往是因为噪音大(即这一维度容易受到随机无关因素的干扰),有些维度方差小,往往是因为噪音小(即这一维度不容易受到环境因素干扰),但PCA将后者这样相对稳定的维度的信息被丢弃了,使得PCA的结果往往是噪声的体现。因此,我们必须人为地去选择像后者这样的因素作为评判因素,从而使得PCA无用武之地,机器学习的应用效果大打折扣。这样的问题有没有什么办法克服呢?
谢谢
正在回答
1回答
相似问题



登录后可查看更多问答,登录/注册







