PolynomialFeatures 带有截距项
PolynomialFeatures 生成出的数据是带有截距项的,而回归函数又重复的添加了截距项,理论上将导致共线性,导致最优解不唯一,而实际从结果看,算法机智地把多项式截距项踢掉了,回归系数为0
我想知道sklearn.LinearRegression是怎么避开共线性的?
如何在sklearn 或者python 中进行共线性检验?
如果回归时我不希望有截距项,应如何设置?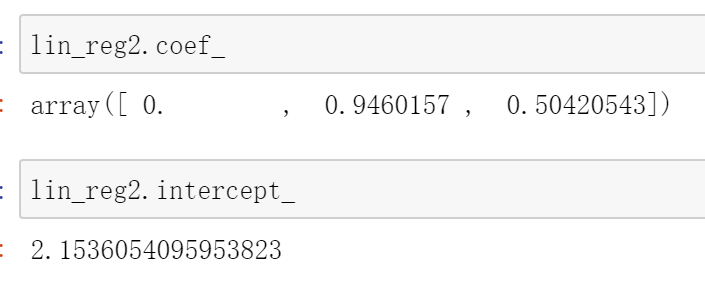
1158
收起
正在回答
1回答

相似问题



登录后可查看更多问答,登录/注册








