关于pipeline中用named_steps得到的系数和截距的问题
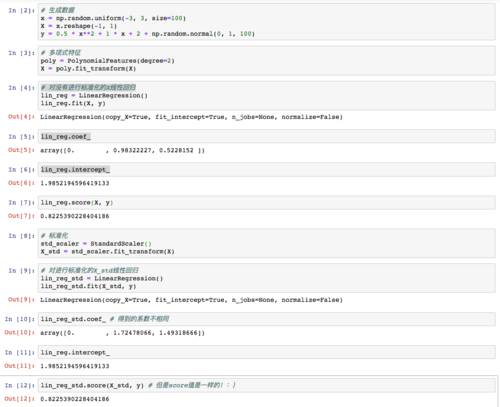
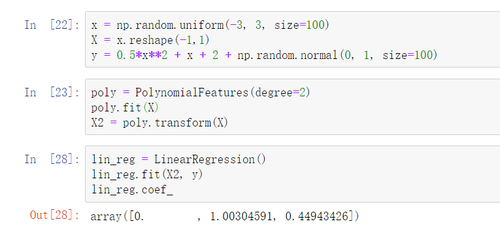
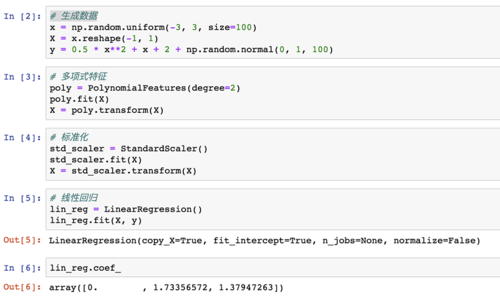
对于这个帖子中所说的解决方案,对于named_steps得到的系数,差距有点大
用
poly_reg.named_steps['lin_reg'].coef_
得到的系数为
array([0. , 1.6418146 , 1.70106747])
1816
收起
正在回答
3回答


相似问题



登录后可查看更多问答,登录/注册








