正在回答 回答被采纳积分+3
4回答
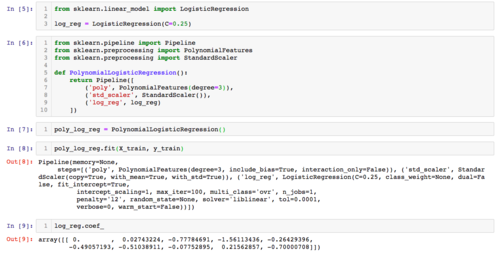
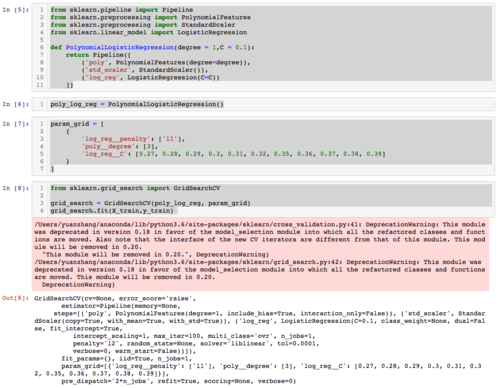
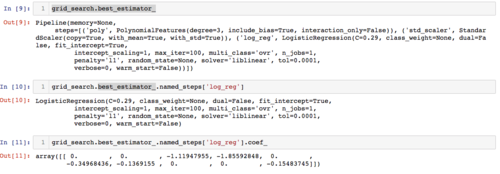

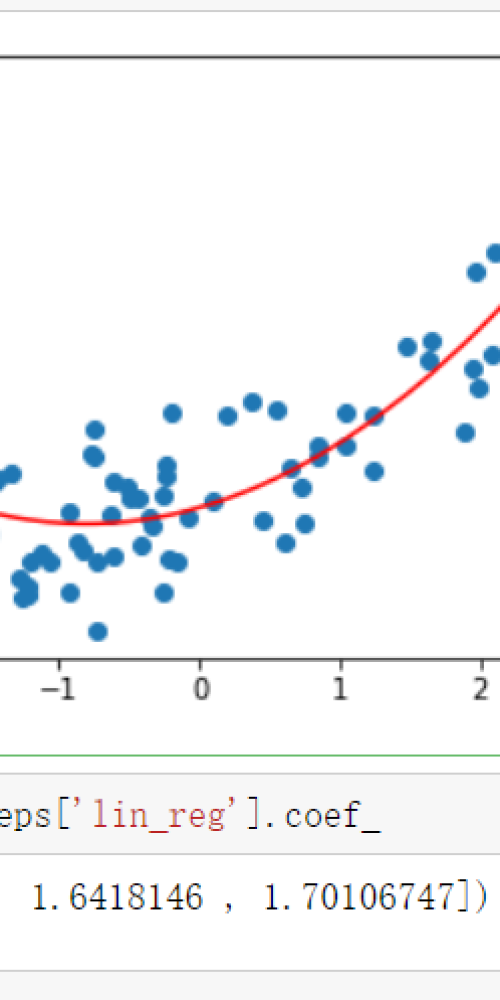
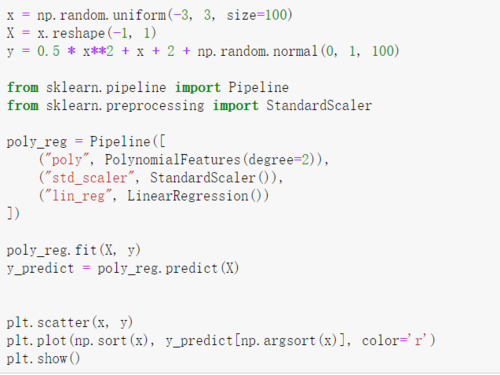

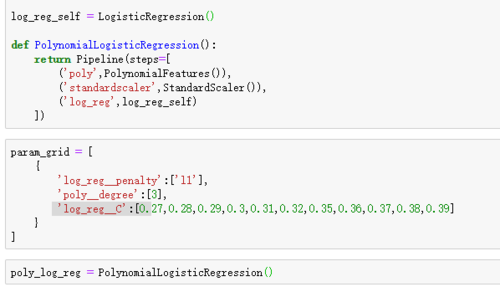
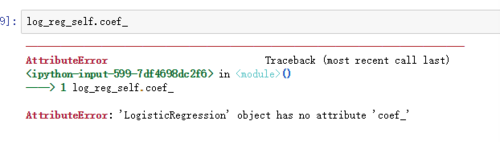
相似问题
channel与pipeline的关系
2537
0
2


GridSearchCV与PipeLine结合使用的疑问
1423
0
6




pipeline 构建在node这步就卡死了
1020
0
6


pipeline几个概念
829
0
1
启动爬虫后不执行pipelines.py怎么解决?
161
0
6


登录后可查看更多问答,登录/注册








