resnet加上batch normalization后的代码
老师您好!
听您的课如醍醐灌顶,就算是新手入门也学到了很多东西,我有如下疑问:我根据您课上的代码,自己动手补充了resnet的代码,实现了数据增强和批归一化,训练了100k步,训练的准确率慢慢上来了,最终稳定在80-90之间;但是test的准确率却异常的低,请问是不是哪里出问题了?
个人运行的代码如下:
import tensorflow._api.v2.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
import pickle
import os
CIFAR_DIR = "K:\project\cifar-10-batches-py"
# 读取文件
def load_data(filename):
"""read data from data file"""
with open(filename, 'rb') as f:
data = pickle.load(f, encoding='bytes')
# print(data[b'data'][0:2], '\n', data[b'labels'])
return data[b'data'], data[b'labels']
load_data(CIFAR_DIR + "/data_batch_1")
# 处理Cifar10数据
class CifarData:
# shuffle:使数据散乱,增强泛化能力
def __init__(self, filenames, need_shuffle):
all_data = []
all_labels = []
#读入数据
for filename in filenames:
data, labels = load_data(filename)
# 多分类任务
all_data.append(data)
all_labels.append(labels)
# 纵向合并,转化为矩阵
# 归一化处理,准确度会上升。若没有归一化,数值比较大,且二分类标签数值在0-1之间,会导致预测偏向一方,在执行SIGMOD时梯度会消失;而使用归一化,就不会偏向一方了。
self._data = np.vstack(all_data)/127.5-1
# 横向合并,因为labels需要是一维向量
self._labels = np.hstack(all_labels)
# print(self._data.shape)
# 当前样本总数
self._num_examples = self._data.shape[0]
self._need_shuffle = need_shuffle
# indicator用于指明在当前数据集上已经把数据集偏移到哪个位置
self._indicator = 0
if self._need_shuffle:
self._shuffle_data()
def _shuffle_data(self):
# 对样本顺序随机化处理
# [0,1,2,3,4,5] -> [5,3,1,0,4,2]
# 生成跟样本数一样多的随机数组下标
p = np.random.permutation(self._num_examples)
# 打乱顺序
self._data = self._data[p]
self._labels = self._labels[p]
def next_batch(self, batch_size):
"""返回对应数量的样本(即要喂入的样本)"""
"""return batch_size examples as a batch"""
# 当前遍历的数据集的结束位置
end_indicator = self._indicator + batch_size
# 结束位置>当前样本数,即终点超出样本范围了
if end_indicator > self._num_examples:
# 需要shuffle则shuffle,当要用时再次取batch_size的样本数(复用数据)
if self._need_shuffle:
self._shuffle_data()
self._indicator = 0
end_indicator = batch_size
# 数据集遍历完了
else:
raise Exception("have no more examples")
# 当batch比所有样本数大,即可以喂的样本不够
if end_indicator > self._num_examples:
raise Exception("batch size is larger than all examples")
# 正常情况,取出相应数量的样本
batch_data = self._data[self._indicator:end_indicator]
batch_labels = self._labels[self._indicator:end_indicator]
self._indicator = end_indicator
return batch_data, batch_labels
#初始化变量
train_filenames = [os.path.join(CIFAR_DIR, 'data_batch_%d ' % i) for i in range(1, 6)]
test_filenames = [os.path.join(CIFAR_DIR, 'test_batch')]
train_data = CifarData(train_filenames, True)
test_data = CifarData(test_filenames, False)
def conv_wrapper(inputs,
name,
is_training,
strides,
output_channels = 32,
kernel_size = (3,3),
activation = tf.nn.relu,
padding = 'same',
):
"""wrapper of tf.layer.conv2d"""
# without bn: conv->activation
# with batch normalization: conv -> bn -> activation
with tf.name_scope(name):
conv2d = tf.layers.conv2d(inputs,
output_channels,
kernel_size,
strides=strides,
padding = padding,
activation = None,
name = name+'/conv2d')
bn = tf.layers.batch_normalization(conv2d,
training = is_training)
return activation(bn)
# 残差连接块:x输入,output_channels输出通道数
def residual_block(x, output_channels):
"""残差连接块"""
# x的最后一维
input_channels = x.get_shape().as_list()[-1]
# 判断输入通道数和输出通道数channels是否一样
# 如果是两倍,需要降采样,设置步长strides为2;需要增加通道数,设置increase_dim为True
if input_channels * 2 ==output_channels:
increase_dim = True
strides = (2,2)
elif input_channels == output_channels:
increase_dim = False
strides = (1,1)
else:
raise Exception("input channel can't match output channel")
conv1 = conv_wrapper(x,
output_channels=output_channels,
strides=strides,
is_training=is_training,
name='conv1'
)
conv2 = conv_wrapper(conv1,
output_channels=output_channels,
strides=(1,1),
is_training=is_training,
name='conv2')
# 增加通道数
if increase_dim:
# [None,image_width,image_height,channel] -> [ , , ,channel * 2]
pooled_x = tf.layers.average_pooling2d(x,
(2,2),
(2,2),
padding='valid',)
padded_x = tf.pad(pooled_x,
[[0,0],[0,0],[0,0],[input_channels//2,input_channels//2]])
else:
padded_x = x
output_x = conv2 + padded_x
return output_x
# 每次降采样输出通道都会乘2
def res_net(x, # 输入
num_residual_blocks, # 残差连接块
num_filter_base, # 最初的通道数目
class_num):
"""residual network implementation"""
"""Args:
- x:
- num_residual_blocks: eg: [3,4,6,3] 每个stage上残差块的多少
- num_subsampling: eg: 4
- num_filter_base
- class_num"""
num_subsampling = len(num_residual_blocks) # 多少次降采样
layers = []
# x:[None,width,height,channels] -> [width,height,channels]
input_size = x.get_shape().as_list()[1:]
# 输入先经过一个普通卷积层
with tf.variable_scope('conv0'):
conv0 = conv_wrapper(x,
output_channels=num_filter_base,
kernel_size=(3,3),
strides=(1,1),
is_training=is_training,
name='conv0')
layers.append(conv0)
# num_subsampling = 4, sample_id = [0,1,2,3]
for sample_id in range(num_subsampling):
for i in range(num_residual_blocks[sample_id]):
with tf.variable_scope("conv%d_%d" % (sample_id, i)):
# num_subsampling = 4, sample_id = [0,1,2,3]
# 每次降采样后输出通道数都要变为原来的2倍
conv = residual_block(layers[-1],
num_filter_base * (2**sample_id))
layers.append(conv)
multiplier = 2**(num_subsampling-1)
# 判断最后的残差是不是符合预期的形状
assert layers[-1].get_shape().as_list()[1:] \
== [input_size[0]/multiplier,
input_size[1]/multiplier,
num_filter_base*multiplier]
with tf.variable_scope('fc'):
# layer[-1].shape : [None, width, height, channel] 四维
# 需要在1、2维度上做pooling(即对width、height做pooling)
# kernal_size: image_width, image_height (池化层核心尺寸=图片大小)从二维的图变成一个像素点
global_pool = tf.reduce_mean(layers[-1],[1,2])
# 全连接后得到logits,是做softmax之前的值
logits = tf.layers.dense(global_pool, class_num)
layers.append(logits)
return layers[-1]
batch_size = 20
# [未知, 3072]
x = tf.placeholder(tf.float32, [batch_size, 3072])
y = tf.placeholder(tf.int64, [batch_size])
is_training = tf.placeholder(tf.bool, [])
x_image = tf.reshape(x, [-1,3,32,32])
#交换通道
x_image = tf.transpose(x_image, perm=[0,2,3,1])
# 数据增强 Data Augmentation
x_image_arr = tf.split(x_image, num_or_size_splits=batch_size,axis=0)
result_x_image_arr = []
for x_single_image in x_image_arr:
# x_single_image:[1,32,32,3] -> [32,32,3]
x_single_image = tf.reshape(x_single_image, [32,32,3])
data_aug_1 = tf.image.random_flip_left_right(x_single_image)
data_aug_2 = tf.image.random_brightness(data_aug_1,max_delta=63)
data_aug_3 = tf.image.random_contrast(data_aug_2,lower=0.2,upper=1.8)
x_single_image = tf.reshape(data_aug_3,[1,32,32,3])
result_x_image_arr.append(x_single_image)
result_x_images = tf.concat(result_x_image_arr, axis=0)
normal_result_x_images = result_x_images /127.5-1
# 神经元图=feature map=输出图像
y_ = res_net(normal_result_x_images, [2,3,2], 32, 10)
loss = tf.losses.sparse_softmax_cross_entropy(labels=y,logits=y_)
# 预测值,第二个参数是指维度,1表示的是下标为1的维度,即取得分最大的作为预测值
predict = tf.argmax(y_, 1)
# 能正确预测的结果
correct_prediction = tf.equal(predict, y)
# 平均准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float64))
# 梯度下降
with tf.name_scope('train_op'):
# 精度10^-3,对loss进行优化
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)
init = tf.global_variables_initializer()
train_steps = 100000
test_steps = 100
# 创建、执行会话
with tf.Session() as sess:
sess.run(init)
for i in range(train_steps):
batch_data, batch_labels = train_data.next_batch(batch_size)
loss_val, acc_val, _ = sess.run(
[loss, accuracy, train_op],
feed_dict={
x: batch_data,
y: batch_labels,
is_training:True
})
# 每500步打印一次训练结果
if (i+1) % 500 == 0:
print('[Train] Step: %d, loss: %4.5f, acc: %4.5f' % (i+1, loss_val, acc_val))
# 每5000步打印一次测试结果
if (i+1) % 5000 == 0:
test_data = CifarData(test_filenames, False)
all_test_acc_val = []
for j in range(test_steps):
test_batch_data, test_batch_labels = test_data.next_batch(batch_size)
test_acc_val = sess.run([accuracy],
feed_dict={
x: test_batch_data,
y: test_batch_labels,
is_training:False
})
all_test_acc_val.append(test_acc_val)
test_acc = np.mean(all_test_acc_val)
print('[Test] Step: %d, acc: %4.5f' % (i+1, test_acc))
结果截图: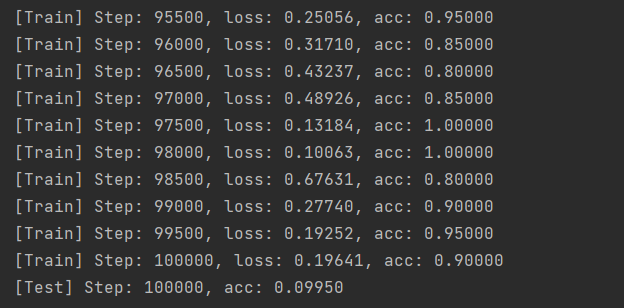
希望得到老师的回复~
1084
收起
正在回答 回答被采纳积分+3
2回答
相似问题
为什么每组batch是50,而下标却只取了前两个值
1459
0
2


batch和epoch
940
0
2


resnet的实现有错误吧。。
1279
0
3
老师我运行您的代码,出错了,我没有改过,请问这是哪里错了
974
0
2


batch-size调优
138
0
4


登录后可查看更多问答,登录/注册




