我Debug调试直接进入item而不是爬虫
老师帮我看看这是为啥啊
from urllib import parse
import re
import json
import requests
import scrapy
from scrapy import Request
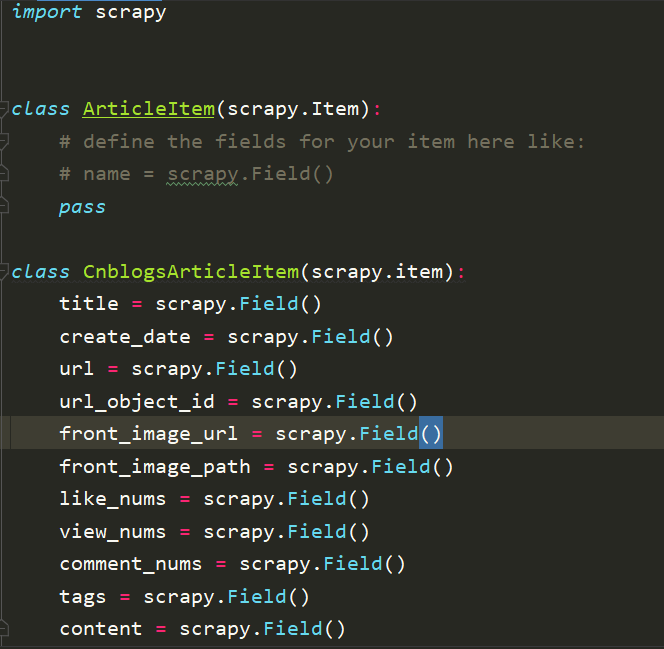
from Article.items import CnblogsArticleItem
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs’
allowed_domains = [‘news.cnblogs.com’]
start_urls = [‘http://news.cnblogs.com/’]
def parse(self, response):
"""
1. 获取新闻列表页面中的新闻url并交给scrapy进行下载后调用相应的解析方法
2. 获取下一页的url并交给scrapy进行下载,下载完成后交给parse继续跟进
"""
# url = response.xpath('//div[@id="news_list"]//h2[@class="news_entry"]/a/@href').extract()
# url = response.css('div#news_list h2 a::attr(href)').extract()
post_nodes = response.css('#news_list .news_block')[:1]
for post_node in post_nodes:
image_url = post_node.css('.entry_summary a img::attr(href)').extract_first("")
post_url = post_node.css('h2 a::attr(href)').extract_first("")
yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":image_url},callback=self.parse_detail)
#提取下一页并交给scrapy进行下载
#使用CSS选择器
# next_url = response.css("div.pager a:last-child::text").extract_first("")
# if next_url == "Next >":
# next_url = response.css("div.pager a:last-child::attr(href)").extract_first("")
# yield Request(url=parse.urljoin(response.url,next_url),callback=self.parse)
#使用Xpath
# next_url = response.xpath("//a[contains(text(),'Next >')]/@href").extract_first("")
# yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self,response):
#获取当前页面的一个页面ID
match_re = re.match(".*?(\d+)",response.url)
if match_re:
# 提取这个页面ID
post_id = match_re.group(1)
#传递参数
article_item = CnblogsArticleItem()
#在页面上需要爬取的信息
title = response.css("#news_title a::text").extract_first("") #标题
# title = response.xpath("//*[@id='news_title']//a/text()").extract_first("")
create_date = response.css("#news_info .time::text").extract_first("") #发表日期
match_re = re.match(".*?(\d+.*)",create_date)
if match_re:
create_date = match_re.group(1)
# create_date = response.xpath("//*[@id='news_info']//*[@class='time']/text()").extract_first("")
content = response.css("#news_content").extract()[0] #内容
# content = response.xpath("//*[@id='news_content']").extract()[0]
tag_list = response.css(".news_tags a::text").extract() #标签
# tag_list = response.xpath("//*[@class='news_tags']//a/text()").extract()
tags = ",".join(tag_list) #将标签列表合并成一个字符串
post_id = match_re.group(1)
#这是一个同步的请求,在不是高并发的情况下也可以用,效率没有异步的高
#拼接路径的时候在最前面加上/这样拼接的路径就会直接加在域名上而不是子路径上
# html = requests.get(parse.urljoin(response.url,"/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)))
# j_data = json.loads(html.text) #这个内容是一个json格式
article_item["title"] = title
article_item["create_date"] = create_date
article_item["content"] = content
article_item["tags"] = tags
article_item["front_image_url"] = response.meta.get("front_image_url","")
#异步请求
yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"article_item":article_item}, callback=self.parse_nums)
# like_nums = j_data["DiggCount"] #点赞数
# view_nums = j_data["TotalView"] #浏览量
# comment_nums = j_data["CommentCount"] #评论数
def parse_nums(self,response):
j_data = json.loads(response.text)
article_item = response.meta.get("article_item","")
like_nums = j_data["DiggCount"] #点赞数
view_nums = j_data["TotalView"] #浏览量
comment_nums = j_data["CommentCount"] #评论数
1021
收起
正在回答
2回答


 这是运行debug后的图
这是运行debug后的图


Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











