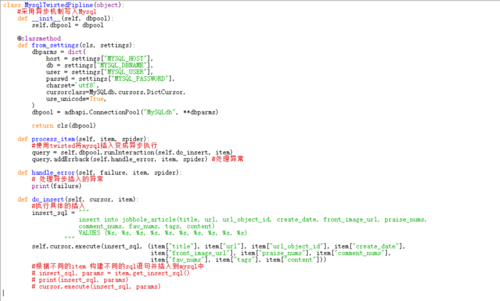
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exporters import JsonItemExporter
from twisted.enterprise import adbapi
import MySQLdb
import MySQLdb.cursors
class ArticlespiderPipeline(object):
def process_item(self, item, spider):
return item
class JsonWithEncodingPipeline(object):
#自定义json文件的导出
def __init__(self):
self.file = codecs.open('article.json', 'w', encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()
class MysqlPipeline(object):
#采用同步的机制写入mysql
def __init__(self):
self.conn = MySQLdb.connect('192.168.0.106', 'root', 'root', 'article_spider', charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
insert_sql = """
insert into jobbole_article(title, url, create_date, fav_nums)
VALUES (%s, %s, %s, %s)
"""
self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
self.conn.commit()
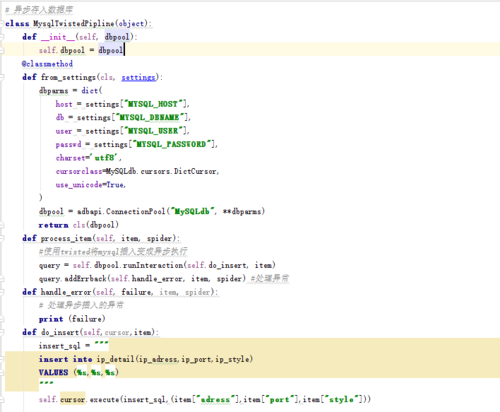
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted将mysql插入变成异步执行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #处理异常
def handle_error(self, failure, item, spider):
#处理异步插入的异常
print (failure)
def do_insert(self, cursor, item):
#执行具体的插入
#根据不同的item 构建不同的sql语句并插入到mysql中
insert_sql, params = item.get_insert_sql()
cursor.execute(insert_sql, params)
class JsonExporterPipleline(object):
#调用scrapy提供的json export导出json文件
def __init__(self):
self.file = open('articleexport.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
if "front_image_url" in item:
for ok, value in results:
image_file_path = value["path"]
item["front_image_path"] = image_file_path
return item建议大家可以将我这里的源码拷贝过去, 然后运行一下 然后对照一下看看哪个地方代码不一样, 一般这种问题都是代码某个地方写错了 或者遗漏了


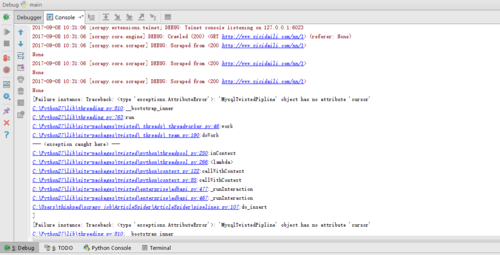
 代码如下
代码如下