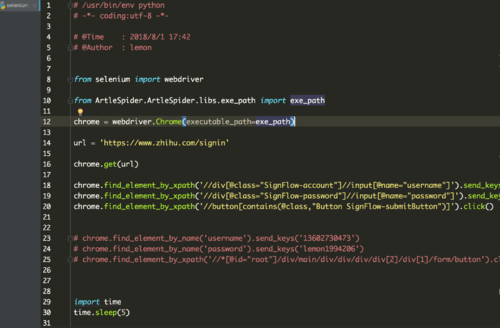
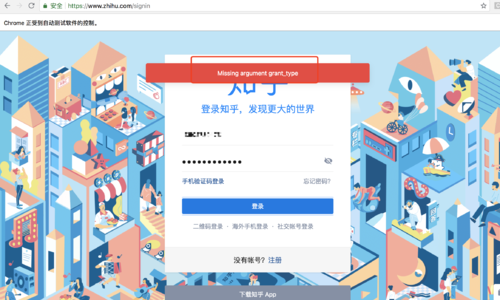
Missing argument grant_type
老师好,按照您最想的视频代码,我试着写了一下,账号密码都能正确输入,但点击登陆的时候,网页出现Missing argument grant_type 这个提示。尽管我尝试手动点击,依旧出现 Missing argument grant_type
正在回答 回答被采纳积分+3
10回答


w84422
2018-08-04 23:46:22

heipepper
2018-08-04 17:40:08
-
哈哈,还没有,还是报Missing argument grant_type

qq_马与草原_04174498
2018-08-04 15:20:44
-
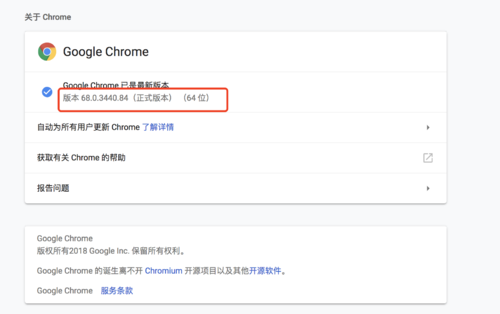
我下载了最新版本的chrome和它对应的driver还是没用,你解决了没
-
chromedriver降到60版本 然后chromedriver使用2.33的版本试试

bobby
2018-08-03 17:24:52
# -*- coding: utf-8 -*-
import re
import json
import datetime
try:
import urlparse as parse
except:
from urllib import parse
import scrapy
from scrapy.loader import ItemLoader
from items import ZhihuQuestionItem, ZhihuAnswerItem
class ZhihuSpider(scrapy.Spider):
name = "zhihu_sel"
allowed_domains = ["www.zhihu.com"]
start_urls = ['https://www.zhihu.com/']
#question的第一页answer的请求url
start_answer_url = "https://www.zhihu.com/api/v4/questions/{0}/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccollapsed_counts%2Creviewing_comments_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Cmark_infos%2Ccreated_time%2Cupdated_time%2Crelationship.is_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.author.is_blocking%2Cis_blocked%2Cis_followed%2Cvoteup_count%2Cmessage_thread_token%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit={1}&offset={2}"
headers = {
"HOST": "www.zhihu.com",
"Referer": "https://www.zhizhu.com",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0"
}
custom_settings = {
"COOKIES_ENABLED": True
}
def parse(self, response):
"""
提取出html页面中的所有url 并跟踪这些url进行一步爬取
如果提取的url中格式为 /question/xxx 就下载之后直接进入解析函数
"""
pass
def parse_question(self, response):
#处理question页面, 从页面中提取出具体的question item
pass
def parse_answer(self, reponse):
pass
def start_requests(self):
from selenium import webdriver
browser = webdriver.Chrome(executable_path="E:/tmp/chromedriver.exe")
browser.get("https://www.zhihu.com/signin")
browser.find_element_by_css_selector(".SignFlow-accountInput.Input-wrapper input").send_keys(
"xxx")
browser.find_element_by_css_selector(".SignFlow-password input").send_keys(
"xxx")
browser.find_element_by_css_selector(
".Button.SignFlow-submitButton").click()
import time
time.sleep(10)
Cookies = browser.get_cookies()
print(Cookies)
cookie_dict = {}
import pickle
for cookie in Cookies:
# 写入文件
f = open('H:/scrapy/ArticleSpider/cookies/zhihu/' + cookie['name'] + '.zhihu', 'wb')
pickle.dump(cookie, f)
f.close()
cookie_dict[cookie['name']] = cookie['value']
browser.close()
return [scrapy.Request(url=self.start_urls[0], dont_filter=True, cookies=cookie_dict)]你把这个代码拷贝过去运行试试 我这里刚才运行了没有问题


相似问题
已安装Pylint,但account下无绿色波浪线:无常量不合法的提示
1405
2
5







[: missing `]'
999
0
1


Missing space before value for key
2782
0
5


登录后可查看更多问答,登录/注册
问题已解决,确定采纳
还有疑问,暂不采纳
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程










