正在回答 回答被采纳积分+3
1回答

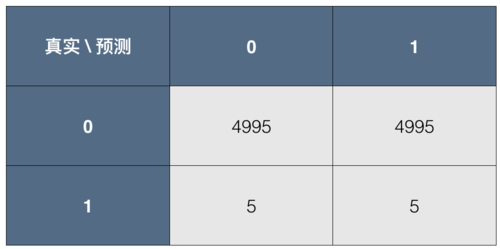
相似问题
f1(test fun)这一步不用语法糖是怎么样一个执行过程
958
0
2


关于多层感知器
1076
1
8




为什么把self.score = score 放在最前面执行结果是-1
1186
0
4


登录后可查看更多问答,登录/注册








