自己编写的f1_score和scikit-learn中的f1_score结果异同的疑问
老师,我对咱们自己编写的f1_score和scikit-learn中的f1_score结果异同存在疑问。那个0.97555555555555551的结果是不是逻辑回归得分的结果啊
from sklearn.linear_model import LogisticRegression
log_reg=LogisticRegression()
log_reg.fit(x_train,y_train)
log_reg.score(x_test,y_test)
咱们编的f1_score是需要计算出精准率和召回率再算吧,我计算的结果和scikit-learn中的f1_score结果一样,是我哪里理解的不对吗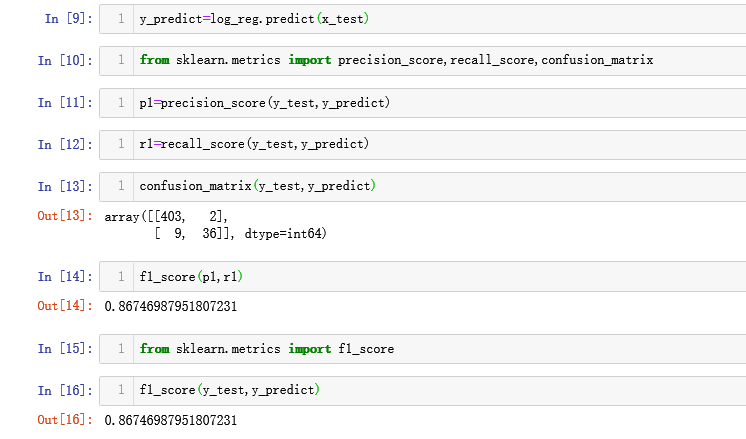
2526
收起









