Gridsearch 的问题
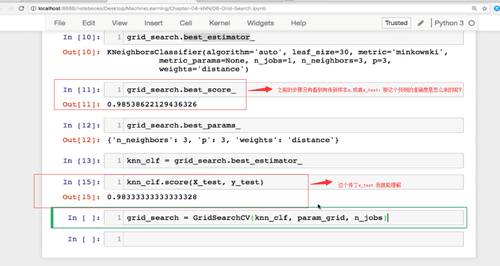
老师,你好,gridsearch中还没predict() 就能通过gridsearch.best_score_ 知道准确度,都没看到哪步传了新的样本,没传新样本怎么计算距离,怎么知道准确度呢?
1709
收起
正在回答
3回答


相似问题
为什么用gridsearch搜索得到的模型精度,比直接用模型差很多呢?
1634
2
2


gridsearch knn
1051
0
1
关于Grid Search处理knn中超参数的问题
2128
0
1
redis分布式锁的问题
1646
0
4




登录后可查看更多问答,登录/注册








