extract报错
这里如果用extract会报错index out of range,我有个地方不明白。url的content一定有,为什么还会报错呢?以及extract()[0]和extract_first(“”)有什么区别呢?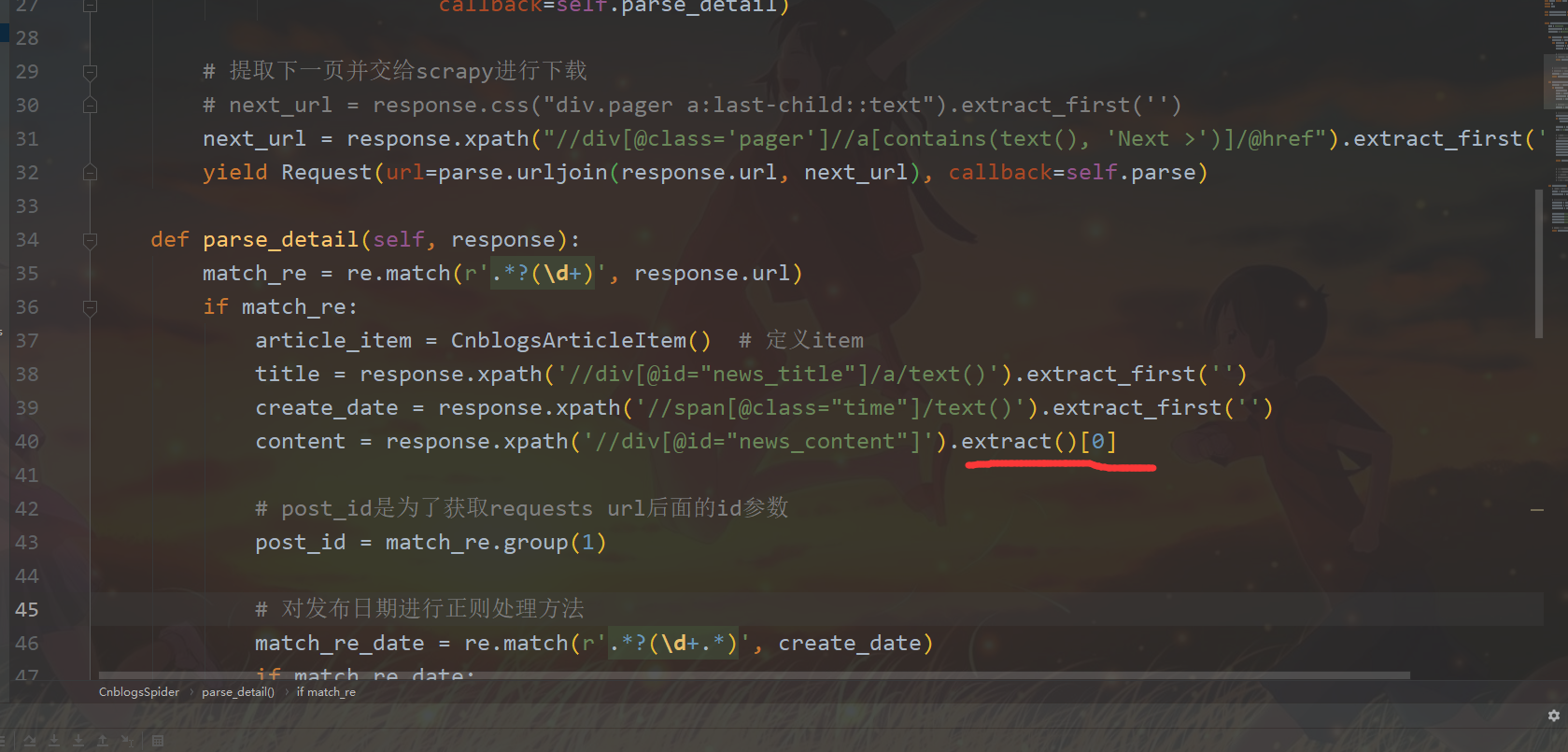
1048
收起
正在回答 回答被采纳积分+3
1回答




Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











