dJ_sgd的i可以不随机取吗?
rand_i = np.random.randint(len(X_b) 可以每次都取相同的值吗?
感觉应该不可以,因为万一那个值是梯度增大的方向就错了,但是有没有可能的不是每次都增大的?
试了下,发现这样子的话,最后的J(theta, X_b, y)每次随后的结果都变化比较大,应该是乱跳了。
python可以把老师视频里的等高图和theta变化画出来吗?
923
收起
正在回答
2回答

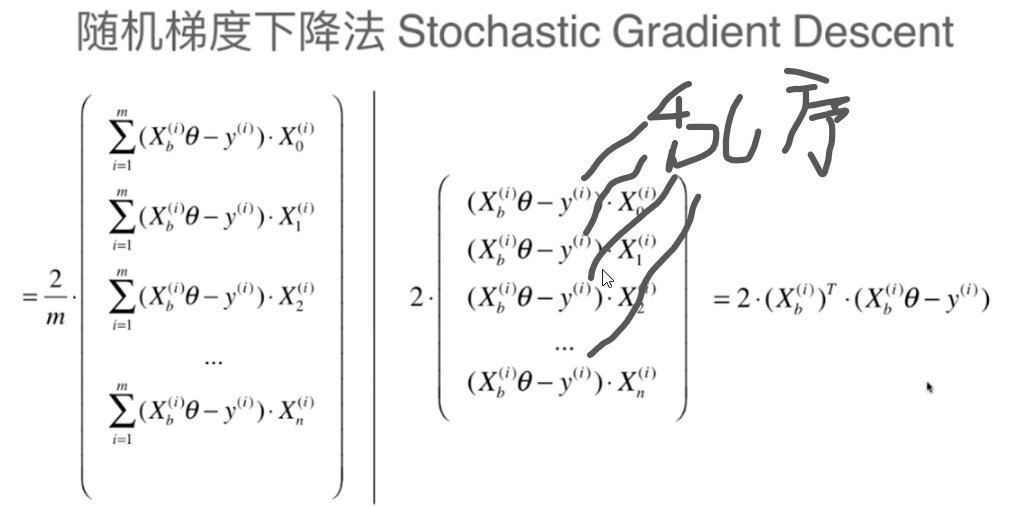 每次求梯度的时候,都是任取了一个i来计算梯度,其中n+1个元素的i都一样,其中i也乱序会不会有意义?
每次求梯度的时候,都是任取了一个i来计算梯度,其中n+1个元素的i都一样,其中i也乱序会不会有意义?相似问题
关于决策树 bagging 与 随机森林的疑问
1827
0
7


关于随机数范围的
1346
3
5
随机梯度下降法的随机究竟体现在哪里?
2840
2
4
B-TREE索引在访问时可以把磁盘随机读取的IO转变成顺序的IO?
1362
0
5


用随机数不如用目前系统时间的毫秒值
1338
0
5


登录后可查看更多问答,登录/注册






