爬虫问题
1.老师,请问是不是 item_loader.add_xpath 这个方法是得不到数据的,拉钩网工作地址,经验,工作类型等等,只要用到xpath就是得不到数据,试了好几次都没获取到,只能换成css选择器才行

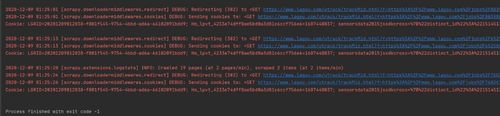
2.爬虫启动后,只爬取了两个数据,就302重定向了,settings里面已经设置
DOWNLOAD_DELAY = 10
COOKIES_ENABLED = True
COOKIES_DEBUG = True
还是不行,应该怎么解决
977
收起
正在回答 回答被采纳积分+3
2回答




Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











