关于 OvR 的疑问
老师好,关于 OvR ,我有些疑问。
您看看,下面我的理解,是否有误。
老师好,如果一个样本有5个,分别对应 A、B、B 、C、D 四个类别。
那么来一个新样本 :
那这个属于A类别概率是 (1+1) / (1+ 5) = 1/3
那这个属于B类别概率是 (2+1) / (1+ 5) = 1/2
那这个属于C类别概率是 (1+1) / (1+ 5) = 1/3
那这个属于D类别概率是 (1+1) / (1+ 5) = 1/3
由于属于B类别概率最高,所以这个新样本,属于 B类别 概率最大?
总觉得哪不对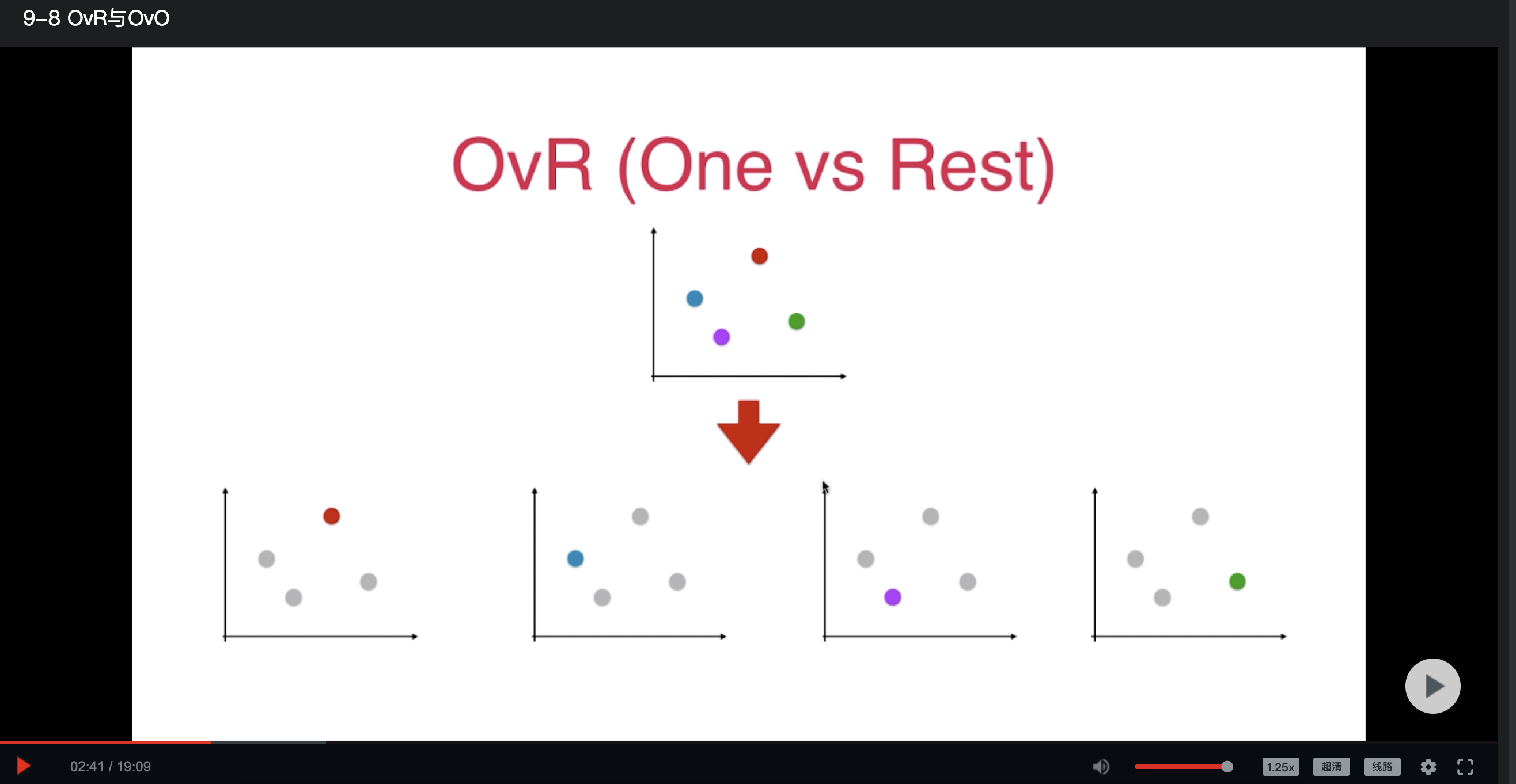
2069
收起
正在回答
1回答
相似问题
ovo 与 ovr
1824
0
5


关于OvO和OvR
1715
0
4
新版本scikit-learn中,关于OvR与OvO的相关问题
2771
0
4
关于OvR与OVO
1203
0
1
【不肯定】OvO AND OvR的实现
1014
0
5


登录后可查看更多问答,登录/注册








