为什么validation的accuracy比train的要高
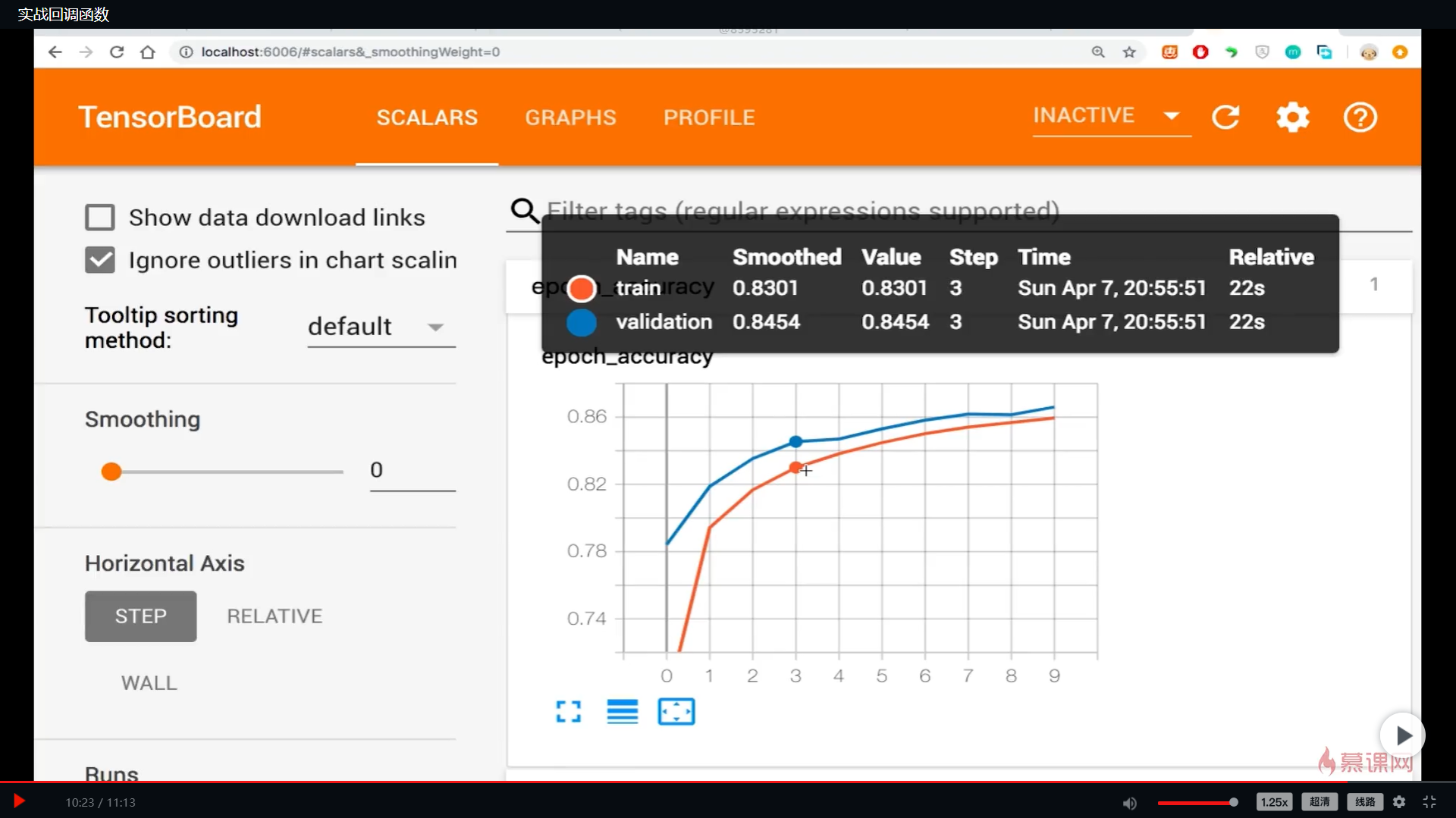
请问为什么validation的准确率要比train的高?按说不应该是在train数据集上的效果要更好吗?这种现象是因为样本分布问题导致的吗?即前面切分完数据集后,训练集和验证集样本分布不同
4196
收起
请问为什么validation的准确率要比train的高?按说不应该是在train数据集上的效果要更好吗?这种现象是因为样本分布问题导致的吗?即前面切分完数据集后,训练集和验证集样本分布不同











