RuntimeError: 。。does not set or modifies parameter layer_size
查看sklearn的官方文档:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html?highlight=randomizedsearchcv#sklearn.model_selection.RandomizedSearchCV.fit
这个fit方法的入参,对应**fit_params dict of string -> object是字典类型了,看不出epochs值要要调为多少?
我试着根据报错提示,把epochs和validation_data的值各加了有个[],如下:
random_search_cv.fit(x_train_scaled,y_train,epochs = [100],
validation_data = [(x_valid_scaled, y_valid)],callbacks = callbacks)
貌似有作用了,
但是出现新的错误类型如下: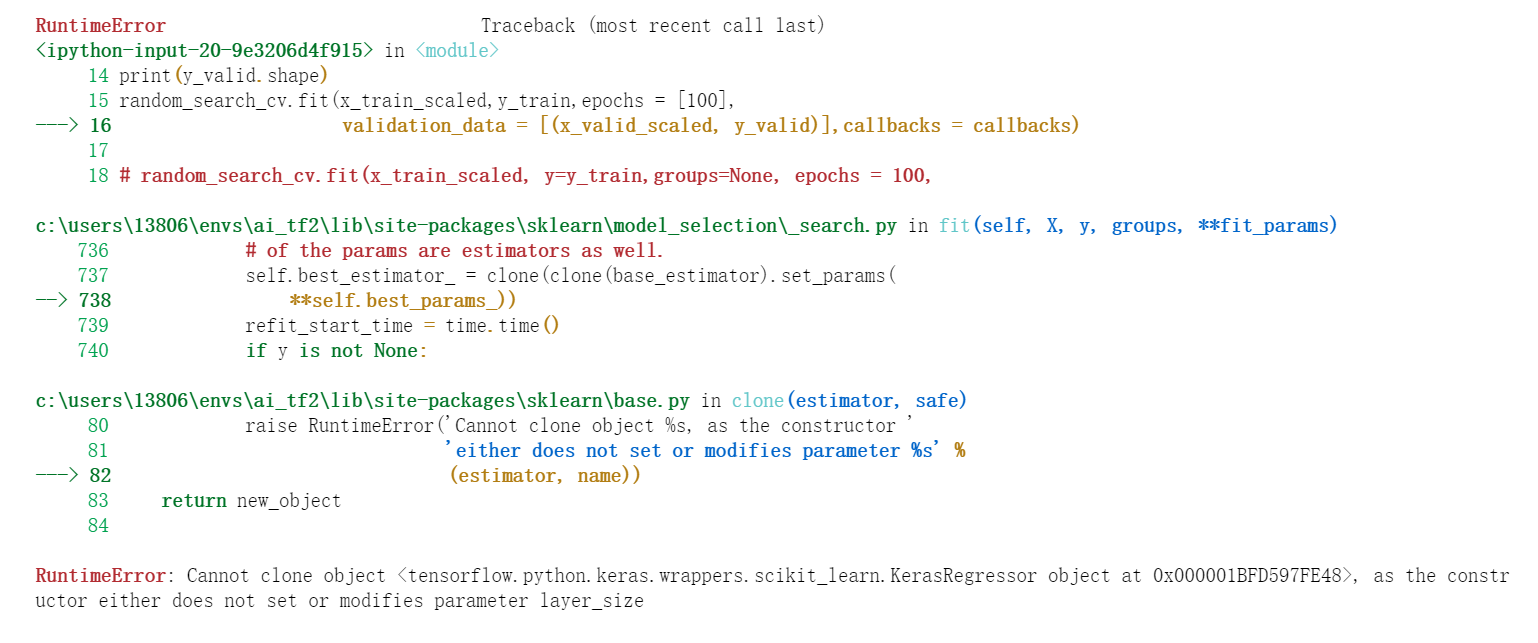
请问:
1、这个加 [100] 的思路是否对?
2、都已经有cv 参数,进行验证集切分了,是否还需要传递 validation_data参数?
3、如上截图,RuntimeError: Cannot clone object,的错误如何解决??
(我试着运行老师github的代码,并且去除后面三个参数,如:random_search_cv.fit(x_train_scaled,y_train),也是运行一段时间后报上面截图错误)
=====
补充贴图:
2795
收起
正在回答
3回答


相似问题







登录后可查看更多问答,登录/注册




