学习曲线很诡异
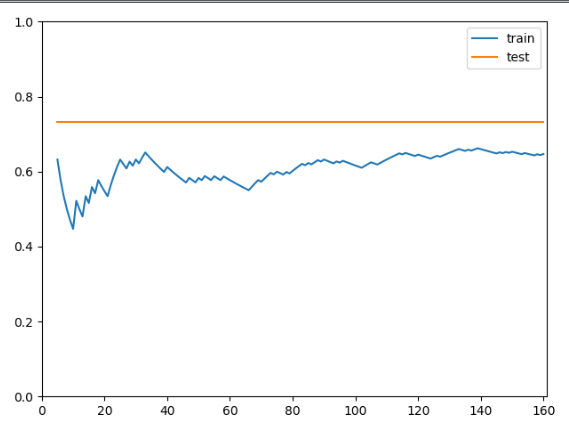 bobo老师,为什么我画出来的学习曲线和您画的完全不一样。。。我拷贝的是您的代码。
bobo老师,为什么我画出来的学习曲线和您画的完全不一样。。。我拷贝的是您的代码。
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm
from sklearn.metrics import roc_curve, auc
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.decomposition import KernelPCA
matrix = np.loadtxt(‘Matrix.txt’)
#数据标准化
standardscaler=StandardScaler()
matrix=standardscaler.fit_transform(matrix)
y=96*[0]+118*[1]
y=np.array(y)
#降维
gamma=0.0018
kpca = KernelPCA(n_components=20,kernel=‘rbf’,gamma=gamma)
X= kpca.fit_transform(matrix)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
clf = svm.SVC(kernel=‘rbf’,gamma=0.001, random_state=10)
def plot_learning_curve(algo, X_train, X_test, y_train, y_test):
train_score = []
test_score = []
for i in range(5, len(X_train) + 1):
algo.fit(X_train[:i], y_train[:i])
y_train_predict = algo.predict(X_train[:i])
train_score.append(mean_squared_error(y_train[:i], y_train_predict))
y_test_predict = algo.predict(X_test)
test_score.append(mean_squared_error(y_test, y_test_predict))
plt.plot([i for i in range(5, len(X_train) + 1)],
np.sqrt(train_score), label="train")
plt.plot([i for i in range(5, len(X_train) + 1)],
np.sqrt(test_score), label="test")
plt.legend()
plt.axis([0, len(X_train) + 1, 0, 4])
plt.ylim([0.0, 1.0])
plt.show()
plot_learning_curve(clf, X_train, X_test, y_train, y_test)
matrix中的数据是一万维的,我用kpca先将这些数据降成20维,然后用svm分类。由于svm分类必须得有两种标签值(两类),如果i从1开始取的话,那喂给svm的数据就只有一个,即1种种类,那它就报错(具体的我也不清楚,反正我从i=5开始取),当我取svm中gamma不同的值时(一个取10,一个取0.001),然后我画出来的学习曲线就非常诡异。。。根本就不知道我画出的这个学习曲线意味着什么。。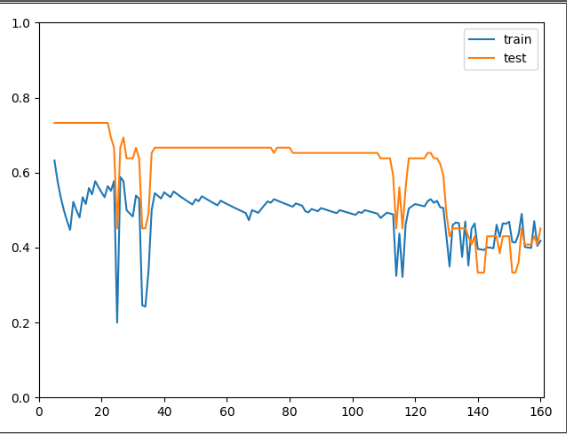
正在回答
1回答

相似问题

登录后可查看更多问答,登录/注册








