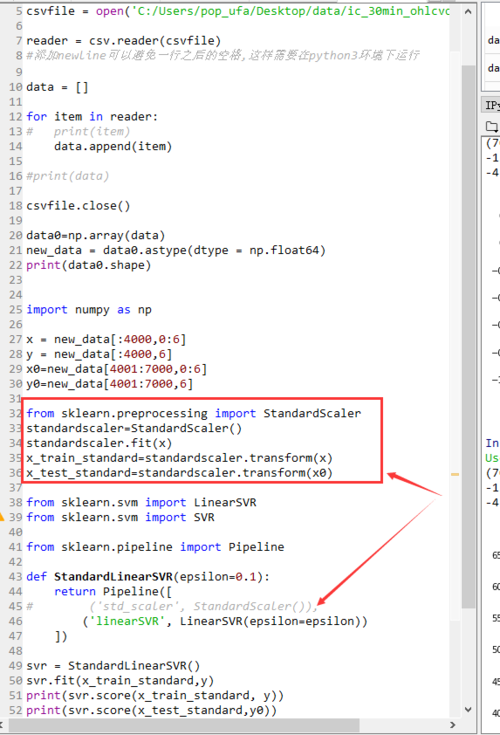
视频中数据预处理x_train=standardscaler.transform(x_train) ,只对x_train做归一化
视频中数据预处理x_train=standardscaler.transform(x_train) ,只对x_train做归一化,不需要对y_train做,是不是因为y是标签值(如果在回归计算时应对对y_train也归一化吧)。
2474
收起
正在回答
3回答


相似问题
for x_train in X_train
1230
0
4




老师所以k=6的意义是什么呢
2457
1
5


关于数据X-train 和y_train之间,他们之间有什么联系?
9173
2
4
test集的归一化
1382
1
1
登录后可查看更多问答,登录/注册








