知乎首页-question链接提取问题
老师您好,请教一个问题:
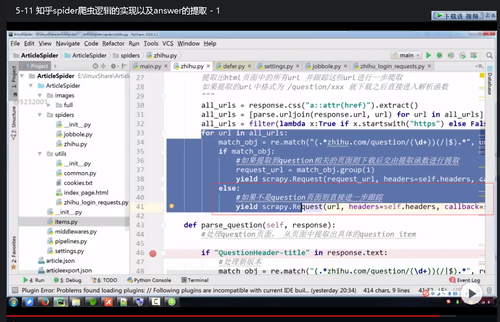
图1您写的回调代码,实现起来好像不是很理想
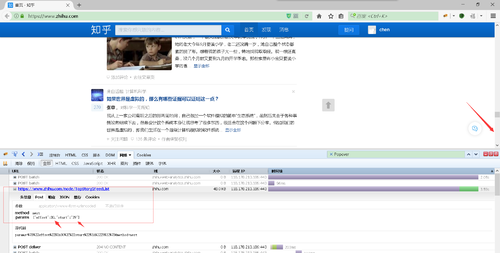
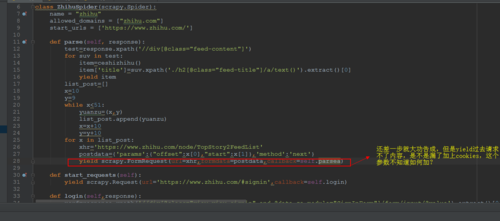
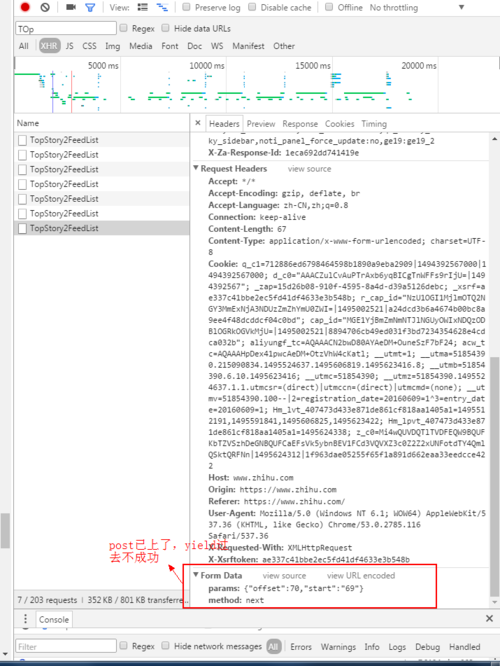
图2是我发现的一个规律,当知乎首页右侧的下拉菜单拉到底后会自动加载出新的页面,抓包看到是通过post提交,当offset,start每次加10就会加载新的页面。
需求:是不是可以通过图2这种方式来多提取question链接,如果可以,是一个什么样的思路。
1925
收起
正在回答
3回答


相似问题



登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程










