知乎首页爬取出来的链接很少
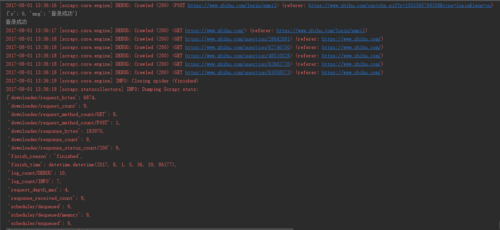
re.match("(.*zhihu.com/question/(\d+))(/|$).*", url)首页爬取出来的问题链接,只有三个。而且把response.text写入html中打开查看,网页不断刷新。是因为知乎的反爬虫策略么,目前有没有解决方案?
1198
收起
正在回答
2回答


相似问题



登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











