启动爬虫后不执行pipelines.py怎么解决?
启动爬虫后不执行pipelines.py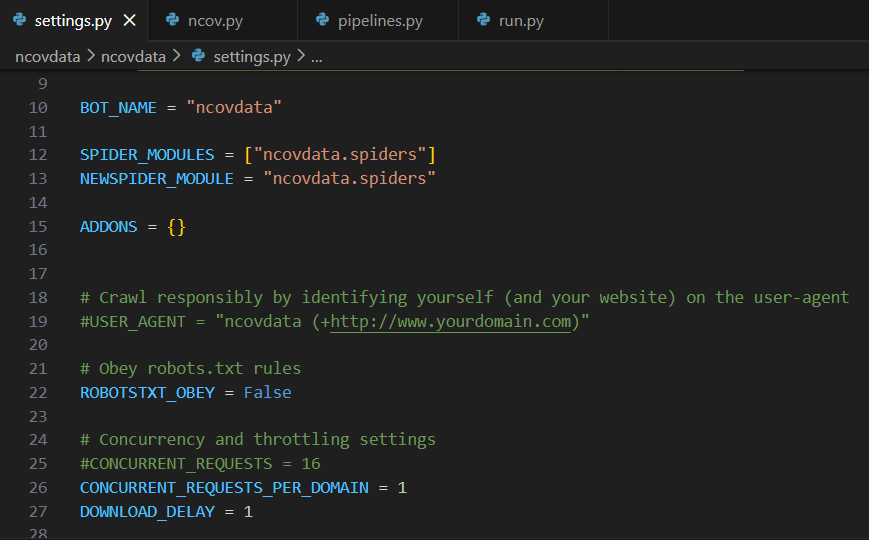
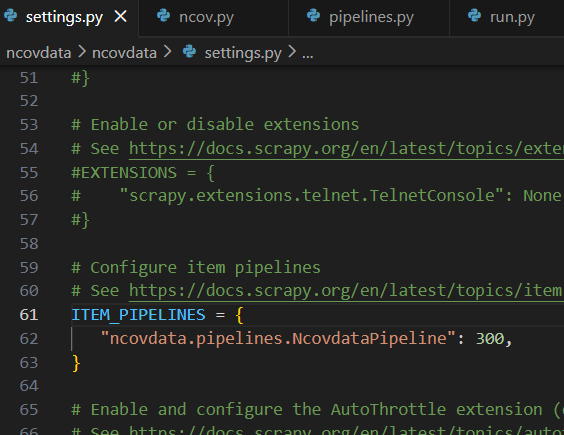
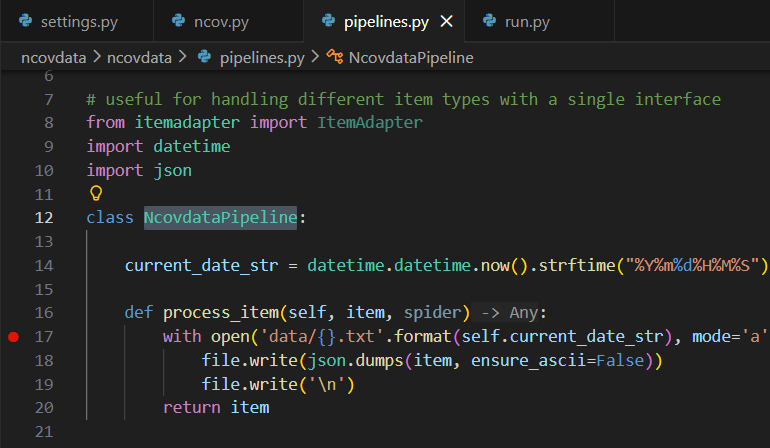
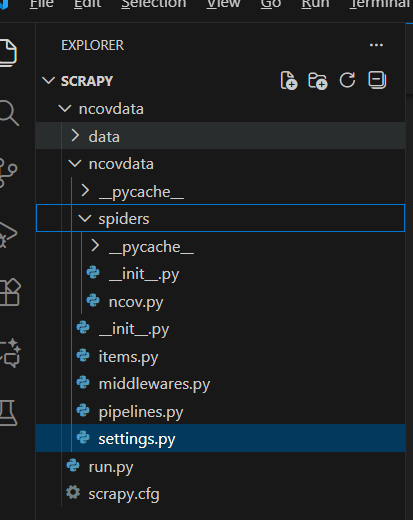
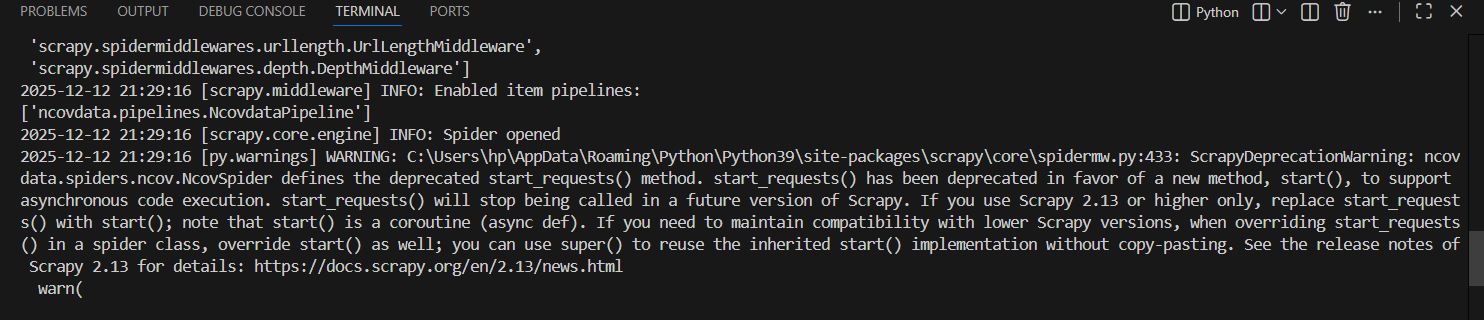 我看了一下日志,似乎是和路径有关,在安装scrapy库时,安装的路径是C:\Users\hp\AppData\Roaming\Python\Python39\site-packages\,但Python安装在C:\Program Files\Python39,和这个有关系吗?现在不知道该怎么解决了,求教
我看了一下日志,似乎是和路径有关,在安装scrapy库时,安装的路径是C:\Users\hp\AppData\Roaming\Python\Python39\site-packages\,但Python安装在C:\Program Files\Python39,和这个有关系吗?现在不知道该怎么解决了,求教
154
收起
启动爬虫后不执行pipelines.py我看了一下日志,似乎是和路径有关,在安装scrapy库时,安装的路径是C:\Users\hp\AppData\Roaming\Python\Python39\site-packages\,但Python安装在C:\Program Files\Python39,和这个有关系吗?现在不知道该怎么解决了,求教








