图片下载到本地无法打开,大小都为1KB
图片下载到本地无法打开,大小都为1KB.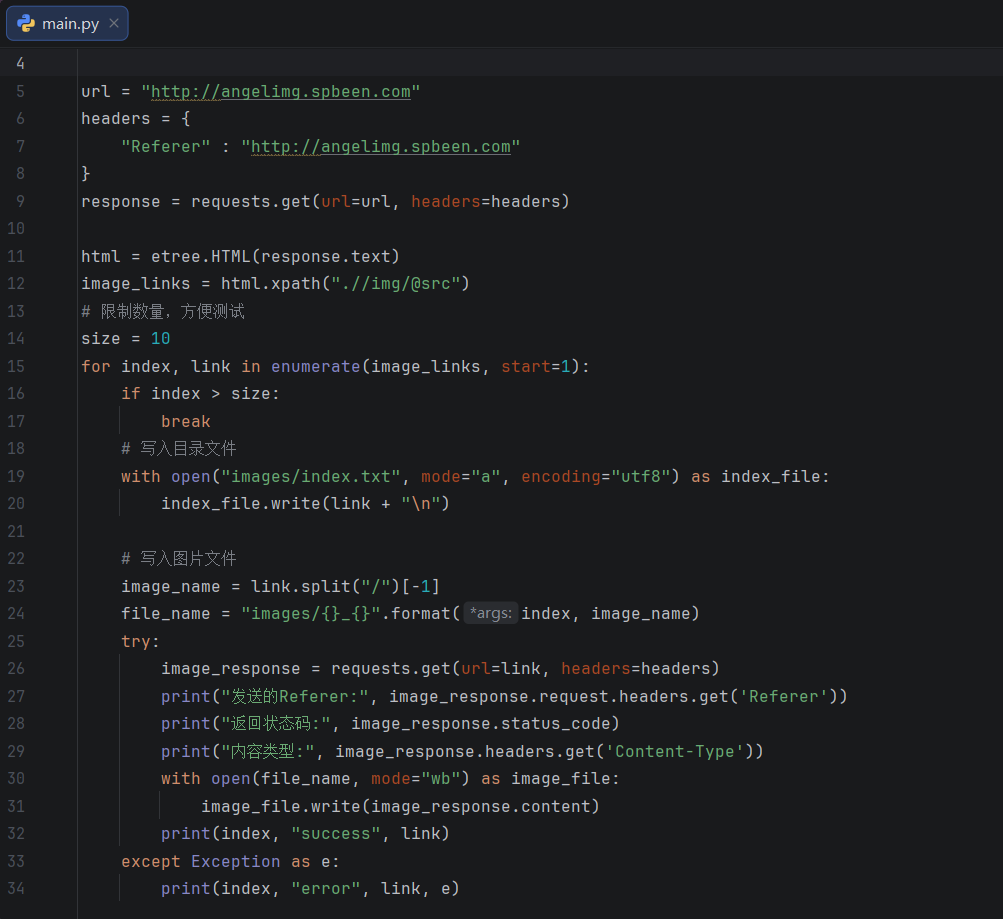
打印link出来的链接是能正确在线访问图片的,
但image_response = requests.get(link, headers=headers)这步,打印image_response.status_code返回403,是网站已经无法扒图片了吗?
headers中Referer已加。
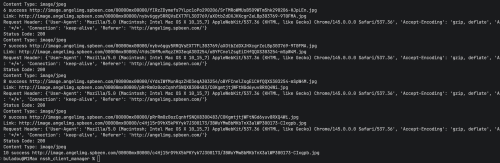
打印日志:
link的链接能正常打开,status_code返回403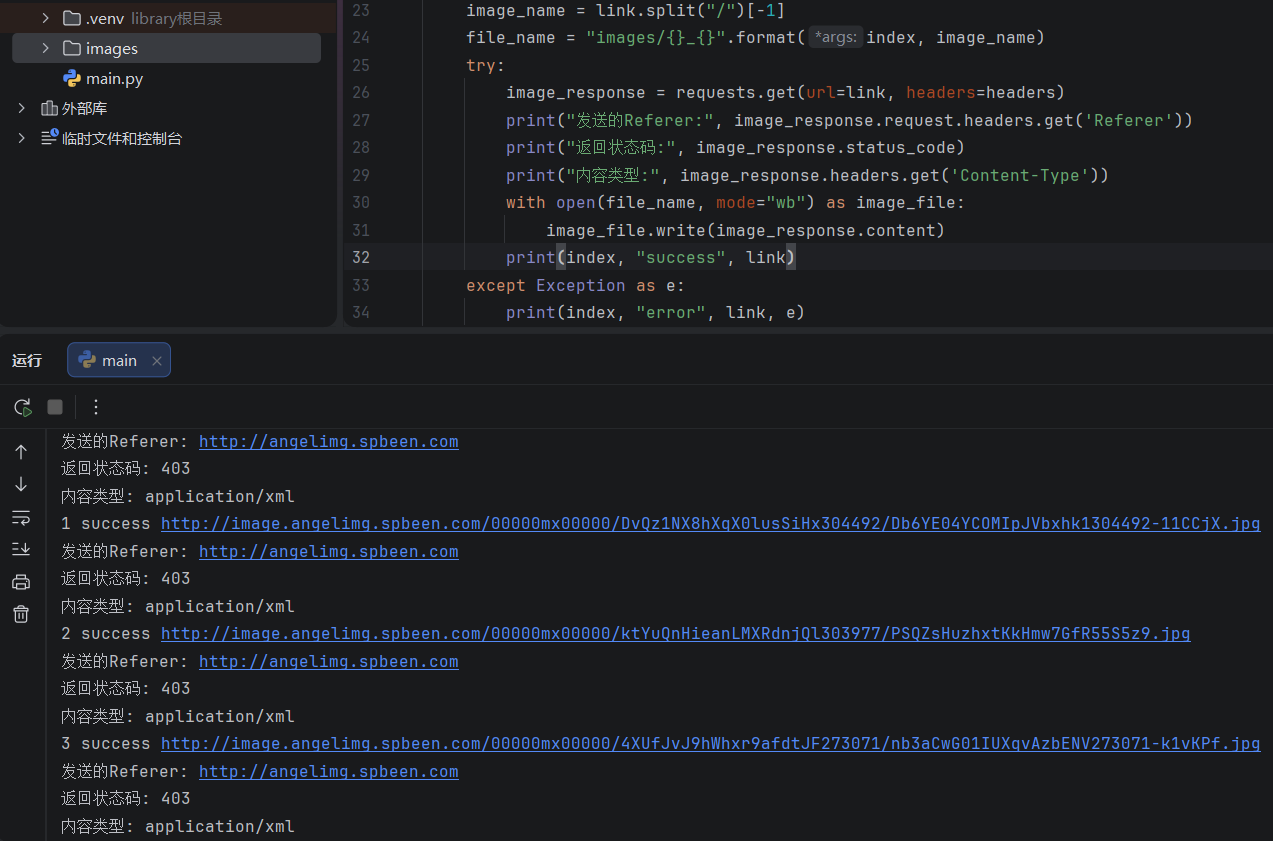
txt文件: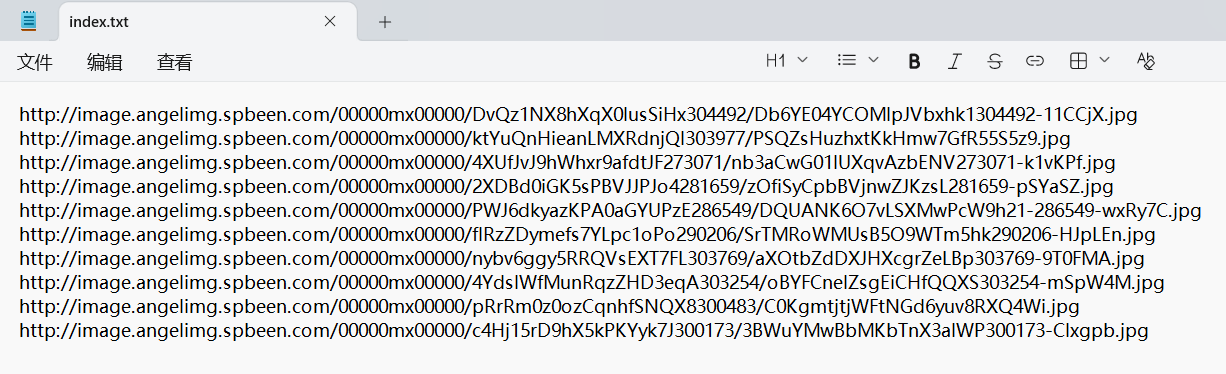
本地图片仅为1KB,无法打开: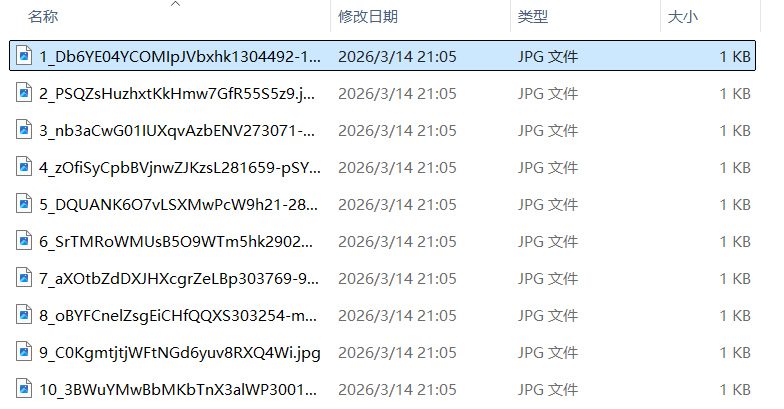

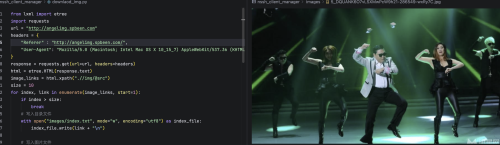
from lxml import etree
import requests
url = "http://angelimg.spbeen.com"
headers = {
"Referer" : "http://angelimg.spbeen.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
}
response = requests.get(url=url, headers=headers)
html = etree.HTML(response.text)
image_links = html.xpath(".//img/@src")
# 限制数量,方便测试
size = 10
for index, link in enumerate(image_links, start=1):
if index > size:
break
# 写入目录文件
with open("images/index.txt", mode="a", encoding="utf8") as index_file:
index_file.write(link + "\n")
# 写入图片文件
image_name = link.split("/")[-1]
file_name = "images/{}_{}".format(index, image_name)
try:
image_response = requests.get(url=link, headers=headers)
print("发送的Referer:", image_response.request.headers.get('Referer'))
print("返回状态码:", image_response.status_code)
print("内容类型:", image_response.headers.get('Content-Type'))
with open(file_name, mode="wb") as image_file:
image_file.write(image_response.content)
print(index, "success", link)
except Exception as e:
print(index, "error", link, e)
112
收起
正在回答
2回答


相似问题







登录后可查看更多问答,登录/注册




