关于SVM模型训练的结果
老师好,几个问题想请教您:
首先假设,我有一个13400的矩阵,400表示的是我有400个样本(其中有A类100个,B类100个,C类100个,D类100个),13表示的是每个样本提取了13个特征值。还有一个1400的矩阵,里面是400个样本对应的标签。(见图片)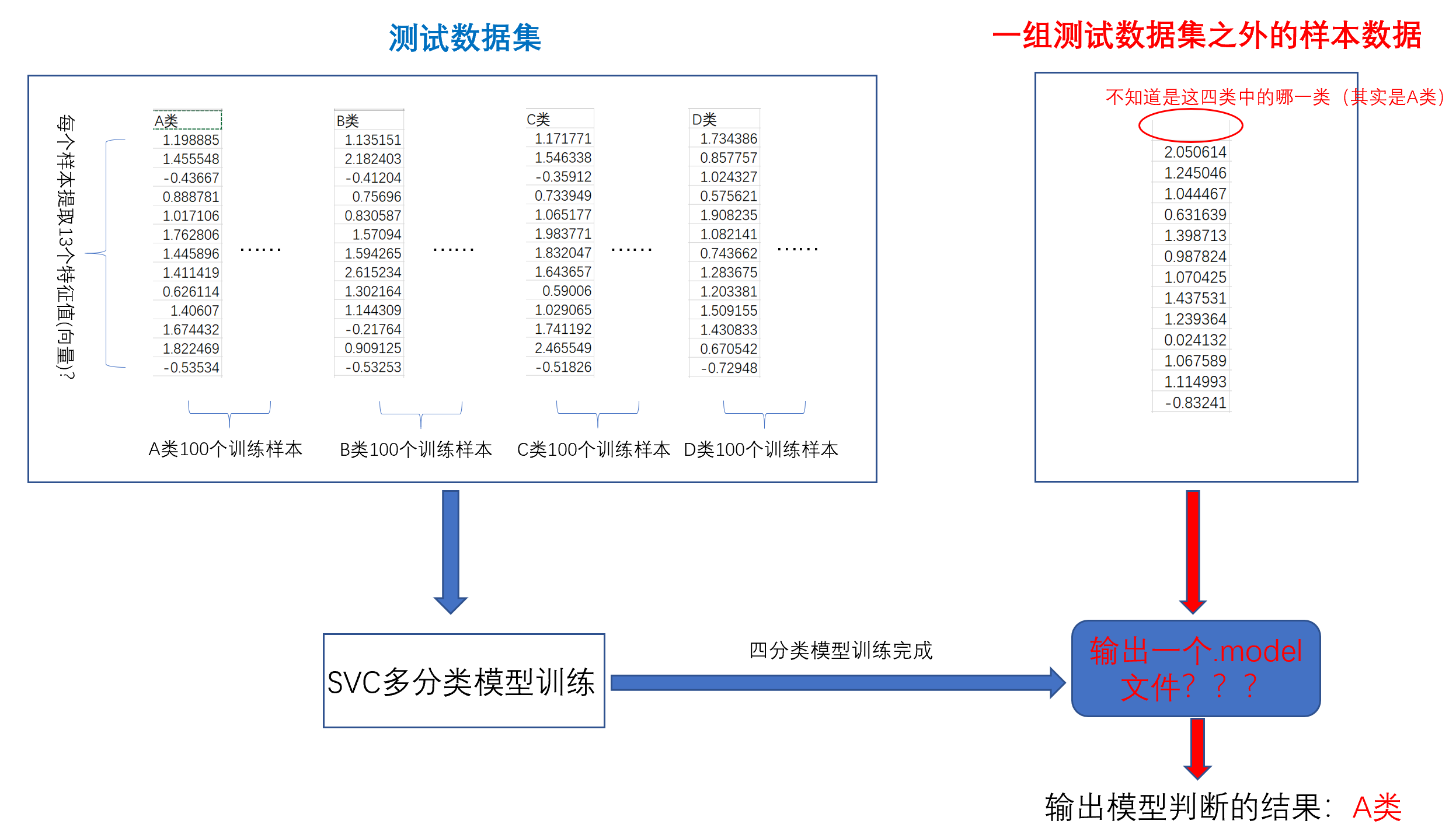
我的问题是:
1.为什么每个样本所提取出来的13个特征值,被称为特征向量,他们不是一个个的数值么?,为什么叫向量??
2.您在视频教程中用的 iris=datasets.load_iris() 是什么?我知道您把数据存到了X中,把对应的标签存到了Y中,但是我没法直观的看到他们是什么样的(至少不像我图片中的形式那么清晰),以什么样子存储的?又是一什么方式被读取来训练模型的?。
3. 如果我有一个excel的文件,或者一个.mat的文件,里面是一个14400的矩阵数据(如我图片所示),我能否直接把它当成是数据集来输入到SVC模块中来训练?(也就是我的目的是把iris替换掉,换成我自己的14400的数据来训练分类模型,我该怎么做~?)
4. 模型训练完以后是什么样子的,是像图片画的那样,产生一个.model 文件么??也就是说:如果我用这个13400+1400的矩阵,训练出了一个SVM的4分类模型,我能否得到一个类似.model一样的文件,它可以直接像.exe那样被我直接拿来用?
5. 最后,假设按如我上面所说,我用sklearn的中的svc训练出了一个4分类.model文件,我怎么测试它的准确率?只能用【交叉验证】么?假如我只想真实地使用这个.model文件来为我解决实际的问题呢??,就是我不想再测试了,我希望直接输入ABCD中某一类的一个训练集之外的样本的特征向量(1*13的矩阵)给这个.model文件,对应的,它就可以给我报出一个它分类后判断的结果(直接告诉我是A类,还是B类,还是C类,还是D类)(这应该是我们用机器学习的普遍的目的吧,我们是想解决一个问题,而不是最后的结果是【交叉验证】后的正确率显示,我们想直观的看到模型给我的判断结果)??
谢谢啦,非常非常期待您的回复。因为手头正好有一个小项目,如果上面这5个问题能搞懂,感觉就能直接拿来解决问题了~~
另外122025382是您的QQ号吧(我在群里面看到的),我申请加您一下哈
正在回答
1回答
相似问题



登录后可查看更多问答,登录/注册







