训练数据集就是模型?还是kNN是模型?
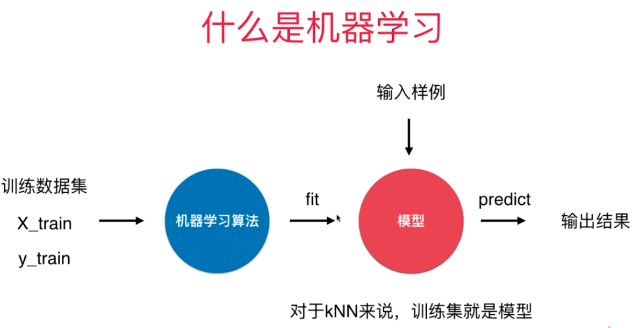
又对这几个说法比较奇怪,怎么训练集就是红色模型,感觉k邻近算法这个过程才是红色模型,然后predict就是把输入样例带进去求到的?
那个蓝色的机器学习算法是不是可以去掉,不是说训练数据集送给fit训练后得到模型,然后模型根据输入样例再进行predict?
2180
收起
正在回答
2回答

相似问题
交叉验证训练的模型用哪个呢?
2591
2
9


感觉如果验证数据叫测试数据,测试数据叫验证数据是不是更好些?
1572
1
2
请教老师 如果评论数据每天有增加,是不是每天都要搞个训练这个论评?
1057
0
3


模型过拟合验证数据集
1305
0
4
平衡数据集对构建模型的影响
1712
0
3


登录后可查看更多问答,登录/注册







