用scrapy-redis爬知乎报错
其他的配置也按照github上配置好了,但是知乎多了一个start_request函数要重载,不知道出错在哪里了。代码如下
class ZhihuSpider(RedisSpider):
name = 'zhihu’
allowed_domains = [‘www.zhihu.com’]
redis_key = "zhihu:start_urls"
url = [“https://www.zhizhu.com”]
headers = {
“HOST”: “www.zhihu.com”,
“Referer”: “https://www.zhizhu.com”,
‘User-Agent’: “Mozilla/5.0 (Windows NT 6.1; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0”
}
start_answer_url = "https://www.zhihu.com/api/v4/questions/{0}/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit={1}&offset={2}&sort_by=default"
def parse(self, response):
"""
利用深度爬取策略,先获取首页所有url,然后进一步爬取
:param response:
:return:
"""
all_urls = response.css("a::attr(href)").extract()
all_urls = [parse.urljoin(response.url, url) for url in all_urls]
for url in all_urls:
match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", url) # 匹配出只包含问题的url
if match_obj:
# 如果匹配到question的url,就回调到用于question解析的方法
request_url = match_obj.group(1)
question_id = match_obj.group(2)
yield scrapy.Request(request_url, headers=self.headers, callback=self.parse_question)
else:
# 如果不是question页面,继续返回爬取
yield scrapy.Request(url, headers=self.headers, callback=self.parse)
def parse_question(self, response):
"""
处理question解析
:param response:
:return:
"""
match_obj = re.match('(.*zhihu.com/question/(\d+))(/|$).*', response.url)
if match_obj:
question_id = int(match_obj.group(2))
item_loader = ItemLoader(item=ZhihuQuestionItem(), response=response)
item_loader.add_css("title", ".QuestionHeader-title::text")
item_loader.add_css("content", ".QuestionHeader-detail")
item_loader.add_value("url", response.url)
item_loader.add_value("zhihu_id", question_id)
item_loader.add_css("answer_num", ".List-headerText span::text")
item_loader.add_css("comments_num", ".QuestionHeader-Comment button::text")
item_loader.add_css("watch_user_num", ".Button.NumberBoard-item .NumberBoard-itemValue::text")
# item_loader.add_css("topics",".QuestionHeader-topics .Popover div::text")
item_loader.add_xpath("topics", "//div[@class='QuestionPage']/meta[@itemprop='keywords']/@content")
item_loader.add_css("click_num", ".NumberBoard-item .NumberBoard-itemValue::text")
question_item = item_loader.load_item()
yield scrapy.Request(url=self.start_answer_url.format(question_id, 20, 0), headers=self.headers,
callback=self.parse_answer)
yield question_item
def parse_answer(self, response):
"""
通过api形式解析answer,先把得到的json数据读取
:return:
"""
ans_json = json.loads(response.text)
is_end = ans_json["paging"]["is_end"]
next_url = ans_json["paging"]["next"]
totals = ans_json["paging"]["totals"]
for answer in ans_json["data"]:
answer_item = ZhihuAnswerItem()
answer_item["zhihu_id"] = answer["id"]
answer_item["url"] = answer["url"]
answer_item["question_id"] = answer["question"]["id"]
answer_item["author_id"] = answer["author"]["id"] if "id" in answer["author"] else None
# 考虑到匿名回答是没有id,所以做判断
answer_item["content"] = answer["content"]
answer_item["praise_num"] = answer["voteup_count"]
answer_item["comments_num"] = answer["comment_count"]
answer_item["update_time"] = answer["updated_time"]
answer_item["create_time"] = answer["created_time"]
answer_item["crawl_time"] = datetime.datetime.now()
yield answer_item
if not is_end:
yield scrapy.Request(url=next_url, headers=self.headers, callback=self.parse_answer)
def start_requests(self):
from selenium import webdriver
browser = webdriver.Chrome(executable_path="C:\python flies\myspider\chromedriver.exe")
browser.get("https://www.zhihu.com/signup?next=%2F")
browser.find_element_by_xpath("//div[@class='SignContainer-switch']/span").click()
browser.find_element_by_css_selector(".Login-content input[name='username']").send_keys("13650098286") # 账号
browser.find_element_by_css_selector(".SignFlow-password input[name='password']").send_keys(
"chrispaul520") # 密码
browser.find_element_by_css_selector(".Login-content button[type='submit']").click()
import time
time.sleep(8) # 等待跳转到首页再取cookies
import pickle
cookies = browser.get_cookies()
cookie_dict = {}
for cookie in cookies:
f = open('C:\python flies\myspider\cookies\zhihu' + cookie['name'] + '.zhihu', 'wb')
pickle.dump(cookies, f) # 将序列化的cookie写入到f中
f.close()
cookie_dict[cookie['name']] = cookie['value']
browser.close()
return [scrapy.Request(url=self.url[0], cookies=cookie_dict, dont_filter=True, headers=self.headers)]
报错的信息:
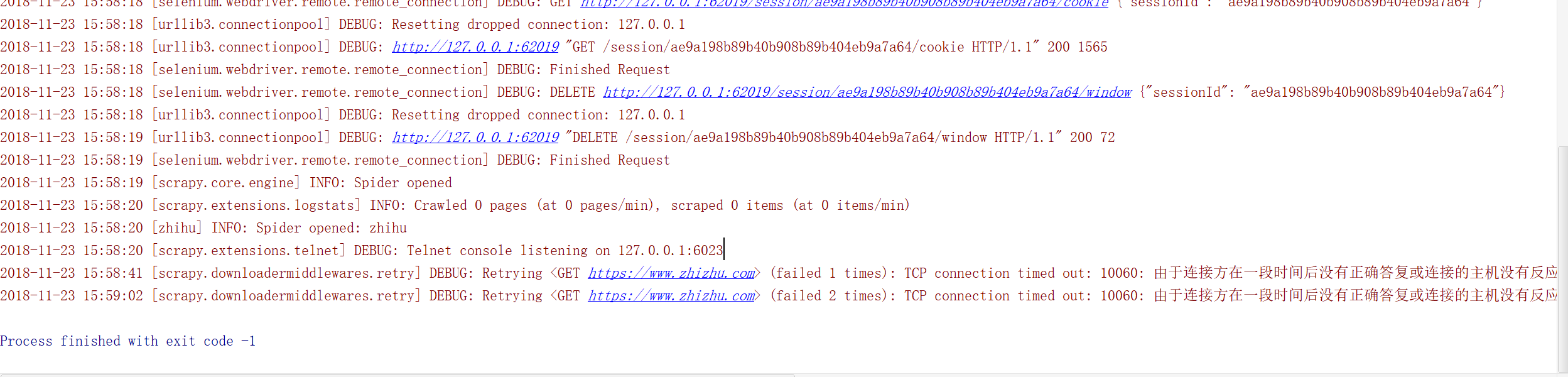
打了断点,并没有进入prase函数,而是卡在监听127.0.0.1:6023那里了,另外已经在redis中lpush了start_url,不知道为什么还是卡在这里
1776
收起
正在回答
2回答
相似问题
scrapyd部署scrapy后无法关闭爬虫
1987
0
1


scrapy redis部署和scrapy的部署有什么不同?
1118
1
1
scrapy-redis怎么做增量爬取
1863
0
5


基于Scrapy-redis的爬虫,模拟登陆如何设置cookies
1348
0
5
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











