关于sklearn中PolynomialFeatures类
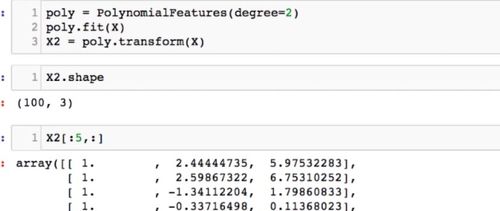
这里升维后加的一列1 是线性回归中X和X_b之间差的那一列1吗,可是加这一列1的操作不是已经封装在类里了吗,这样不就重复了
1403
收起
正在回答
1回答
相似问题
PolynomialFeatures 带有截距项
1114
0
4


polynomialfeatures中的参数
1376
2
1
关于生产环境下,调用 sklearn 接口的疑问
1217
0
4
sklearn 随机森林
412
0
1
登录后可查看更多问答,登录/注册








