拉勾网重定向无法爬取
在用scrapy进行拉勾网站的爬取,我想抓取python 相关的职位,start_url="https://www.lagou.com/zhaopin/Python/?labelWords=label",
但是我用pycharm调试功能查看,爬虫运行之后,会把这条链接重定向到
"https://www.lagou.com/utrack/trackMid.html?f=https%3A%2F%2Fpassport.lagou.com%2Flogin%2Flogin.html%3Fmsg%3Dvalidation%26uStatus%3D2%26clientIp%3Dxx.xx.xx.xx1&t=1507458004&_ti=1"这个地方,然后查看response.text也没有内容,也增加了headers,可是在浏览器里却可以正常访问,排查了好长时间,始终不知道拉勾网是怎么知道scrapy请求和浏览器请求区别的,没有找到知道问题所在,为啥连第一个url都不能请求,还有一点我继承的是Spider类,这个连接的内容在scrapy shell 里边却可以获取.
以下截图分别是源码/控制台输出/response.text内容/scrapy shell请求url,并查看text内容:
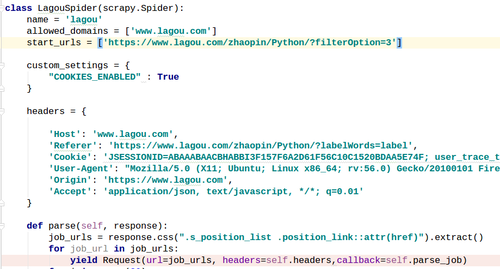

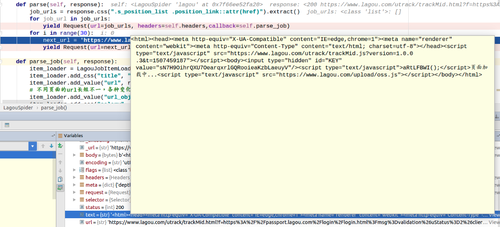
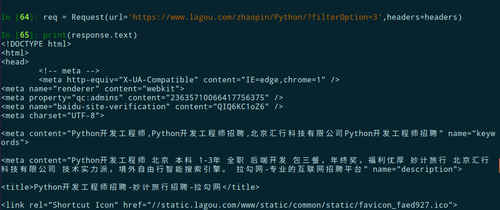
求老师解惑
1904
收起
正在回答 回答被采纳积分+3
3回答



相似问题



登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











