拉勾网站爬取
拉钩网站爬取思路
- 用requests.session() 获取到所有城市的名称 然后请求具体的每个城市
- 发现招聘信息在"https://www.lagou.com/jobs/positionAjax.json?px=default&city=%s&needAddtionalResult=false" % city 但是请求这个是带上了cookie的 而cookie的来源是在请求每个具体的城市url
所以先请求 https://www.lagou.com/jobs/list_python/p-city_%s?px=default
在请求 “https://www.lagou.com/jobs/positionAjax.json?px=default&city=%s&needAddtionalResult=false” % city
在过程中遇到referer反扒 加上referer之后 ip限制 改用ip代理
存入数据库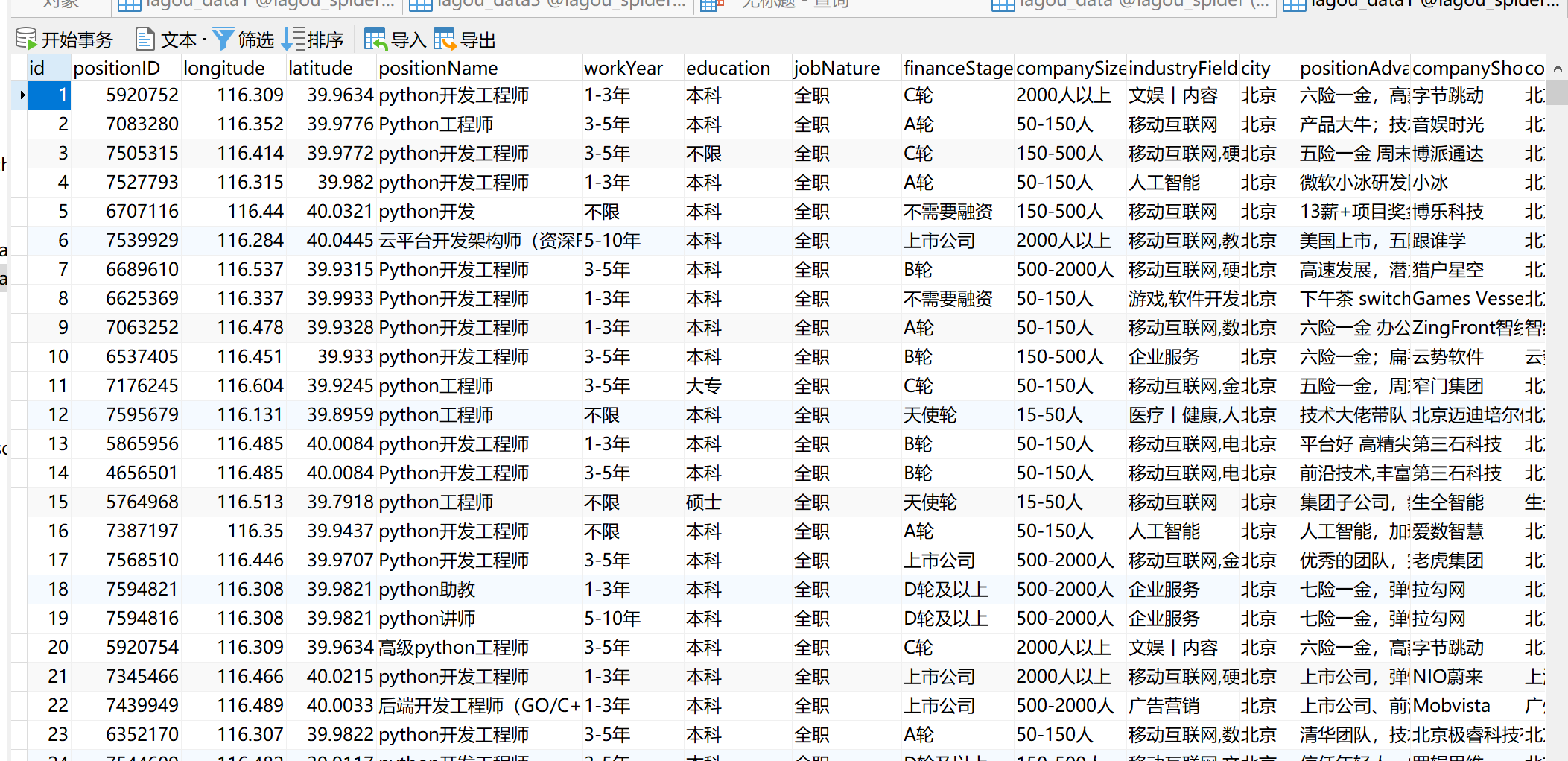
- 发现爬虫进行到中途会莫名停止 应该是城市太多的原因(360个)
而且还没有我写死一个城市或者二个城市爬取的数据量大(有些偏僻城市)。发现偏僻城市会用一些上海 广州 等大城市页面数据来进行替换 然后就测试
city_list = [“宁波”, “常州”, “沈阳”, “石家庄”, “昆明”, “南昌”,
“南宁”, “哈尔滨”, “海口”, “中山”, “惠州”, “贵阳”, “长春”, “太原”, “嘉兴”, “泰安”, “昆山”, “烟台”, “兰州”, “泉州”] 少量城市 是能爬取下来的
想问下老师出现这种不报错 但是中途出现停止情况的原因是啥 是因为服务端限制了请求的次数吗?还有就是只要我一改用多进程 程序马上停止 不会报错 也不知道为什么。
943
收起
正在回答 回答被采纳积分+3
1回答



Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











