page_source 打印出来仍然是网页源码
老师,我按照8-1章节的selenium的print(browser.page_source)打印出加载后的html页面,但是为什么print出来的仍然是和网页源码一样的html?
直接用selenium的browser.find_element_by_css_selector()函数,是可以定位到元素。
但是用Selector(text=browser.page_source)以后,无法定位元素,因为下载的不是渲染以后的html,下载的仍然是网页源码。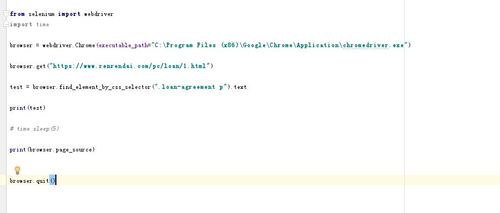
2524
收起
正在回答
3回答

相似问题
老师selenium怎么获取单页面vuejs网站解析后的源码?
455
0
5


curl获取静态地图,输出乱码,请教老师
1158
0
4






vue-loader,自定义代码块,打印出来是undefined
1104
0
4






登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











