准确率结果相同时,不同超参数值的选择偏向
在第4-5课程中,搜索明科斯基距离相应的p时,由于我的算法与老师的略有不同,如下图,因best参数更新在于当前分数大于最好分数,则其只记录一组最好分数的记录 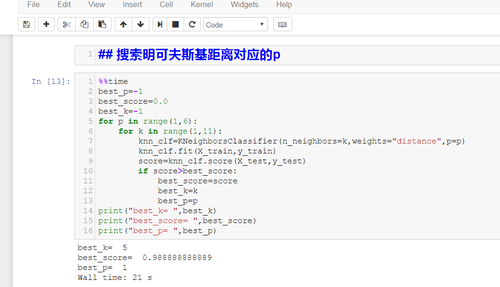
则 当最好分数为0.988888888889存在多组记录,如 我的bset_p=1,best_k=5 而老师的是bset_p=2,best_k=3
那么带来的问题是对于这两种结果一样,但参数数值不同的超参数应该怎么选取,应系统考虑哪些条件?(算法运行时间?)
1146
收起
正在回答
1回答
相似问题
数值检索不准确
400
0
3


当训练次数达到一定程度时准确率会降低?
3282
0
3


如何判断欠拟合是因为模型选择错误还是超参数选择错误?
2156
2
15





关于阈值变动后,概率的选择
1103
0
2
登录后可查看更多问答,登录/注册







