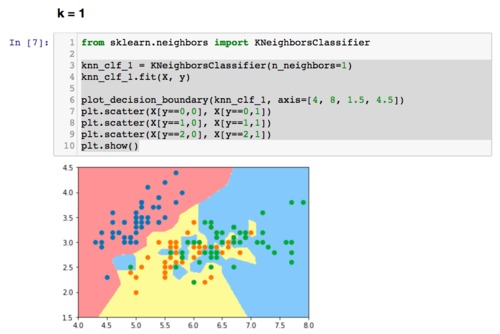
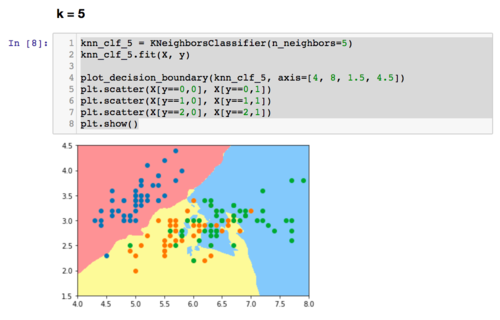
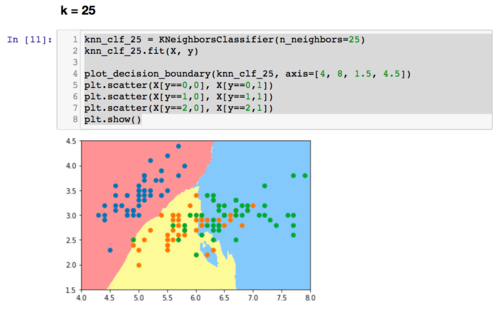
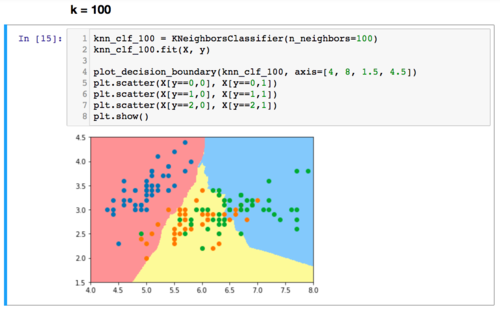
为什么knn算法的k越小模型会越复杂?
knn不是计算出样本与每个样本的距离后,对前k个距离最近的样本进行投票,然后最高票胜出。那为什么说k越小越容易过拟合呢?
8731
收起
正在回答
1回答
相似问题
训练数据集就是模型?还是kNN是模型?
2128
2
11




KNN模型也有模型正则化的操作吗?
1483
1
3


关于KNN算法的中k的取值的问题
4034
4
4
请问设置算法通常会设置一个常数,怎么设置?有什么用?
1336
1
3
登录后可查看更多问答,登录/注册







