关于精准率和召回率的平衡点似乎都是在0左右
老师您好,本节课中的精准率和召回率的绘图可以看出平衡点都是在决策边界为0的时候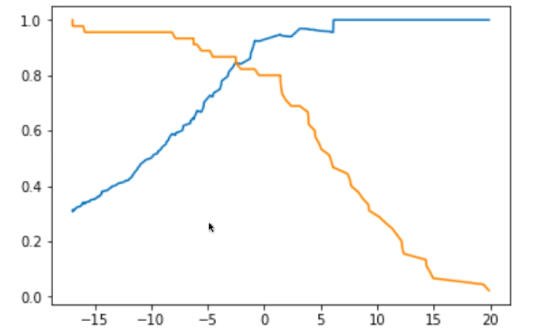
是否是因为逻辑回归在训练过程中使用的是>=0的决策边界,从而得到的theta值作用于测试数据集的时候也是使得其精准率和召回率在决策边界为0时达到平衡。
941
收起
正在回答 回答被采纳积分+3
1回答
相似问题
老师 对精准率和召回率的区别的直观理解的问题
1510
2
4


多分类如何根据混淆矩阵求准确率、精准率、和召回率?
8105
1
14
小样本要使用精准率和召回率吗
1414
0
1
Svm精准率,召回率问题
2349
0
4
精准率和召回率相互制约问题
928
0
1
登录后可查看更多问答,登录/注册








